
The Crucial Interplay Between Context Engineering and Memory Engineering in Agentic AI Systems
As artificial intelligence agents evolve to handle increasingly complex and extended workflows, a critical challenge emerges: ensuring they can effectively manage and utilize information across multiple interactions and sessions. This evolution highlights the distinct yet interconnected roles of context engineering and memory engineering, two fundamental disciplines that govern an agent’s ability to retain and apply knowledge. Failures in these areas often manifest as dropped constraints, misplaced information, or the unintended bleeding of context from one task to another, creating a complex debugging scenario where no single component appears solely at fault. The root cause, however, frequently lies in the intertwined, and sometimes conflated, practices of context and memory engineering. Understanding these disciplines individually and in concert is paramount to building robust and scalable AI agent systems capable of sustained performance.
The Dual Pillars of Agentic AI: Context and Memory Engineering
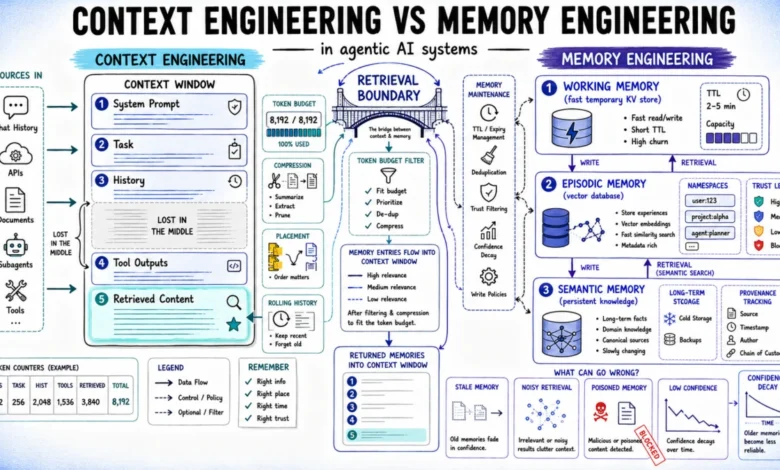
Context engineering focuses on the immediate, ephemeral needs of a single inference call. It dictates what information is included, how it is compressed, its precise placement within the model’s context window, and what elements are ultimately discarded. Upon the completion of a call, this context is cleared, making it a transient state.
In contrast, memory engineering addresses the persistence of information beyond a single interaction. It encompasses the systems and policies responsible for writing, storing, retrieving, updating, and governing data that future interactions can leverage. When an agent recalls information from a prior session, coordinates with other agents, or applies user preferences learned weeks ago, it is relying on memory engineering. While context engineering determines the immediate informational landscape for a given request, memory engineering dictates what information endures across requests, how it is maintained, retrieved, and validated over time.
The table below illustrates the fundamental differences and overlaps:
| Aspect | Context Engineering | Memory Engineering |
|---|---|---|
| Scope | Single inference call | Across calls, sessions, and agents |
| Data Location | Within the model’s active window | External stores (vector DB, K/V, relational) |
| Primary Problem | What to include and how to arrange it | What to persist, retrieve, and trust |
| Failure Points | Window overflow, incorrect placement, noise | Retrieval misses, staleness, poisoning, lack of write policy |
| Engineering Surface | Prompt structure, compression, token budgeting | Storage schema, retrieval strategy, write/update policies |
| Data Lifespan | Duration of one LLM call | Varies by memory type |
Context Engineering: Orchestrating the Information Window
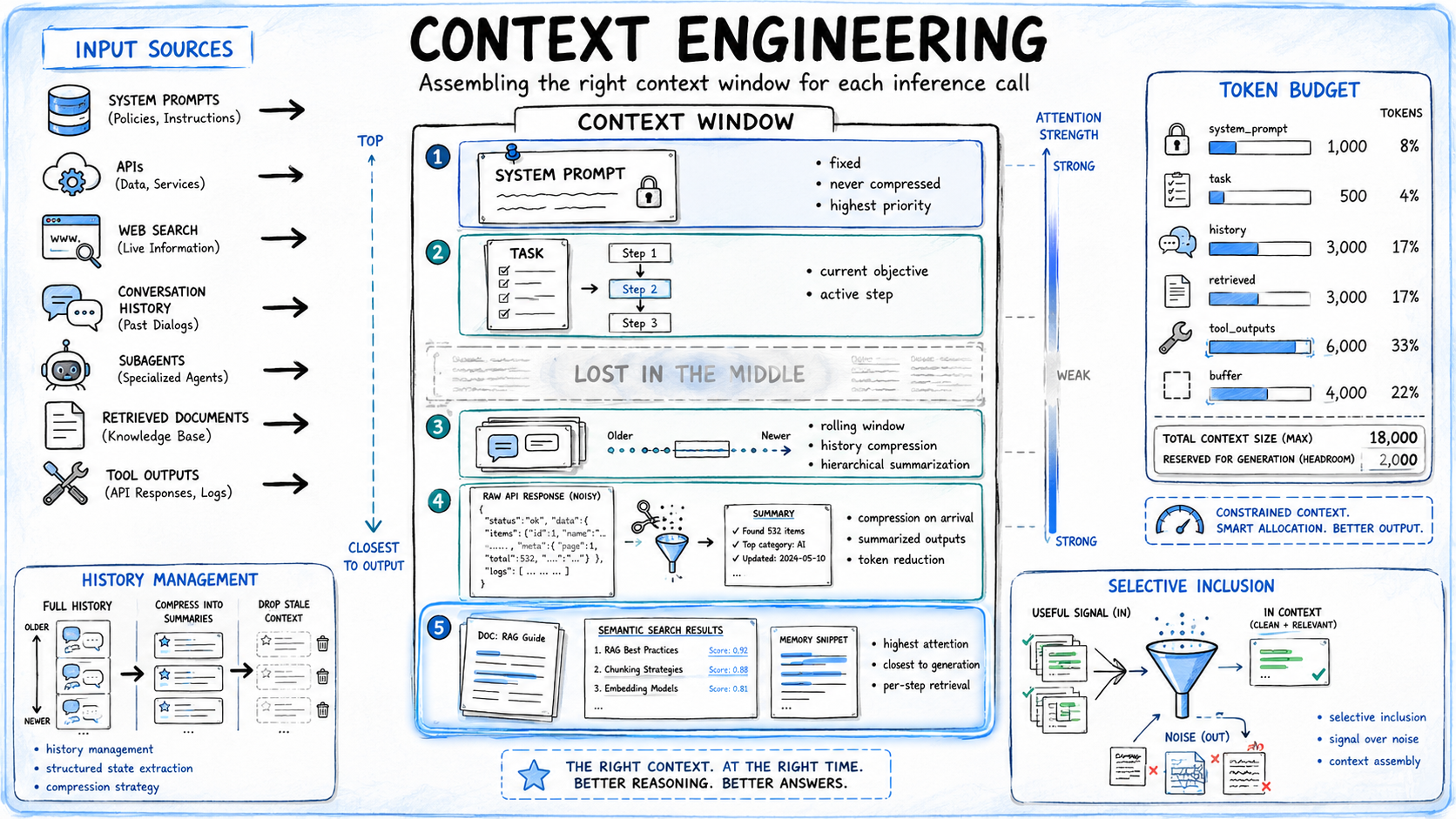
For AI agents engaged in multi-step workflows, each inference call involves assembling a context window from various sources: system prompts, task descriptions, conversation histories, tool outputs, and retrieved documents. Context engineering encompasses the strategic decisions about the contribution, format, and position of each component within this window.
Selective Inclusion and Compression
A core principle of context engineering is that not all available information should be incorporated. A database query returning hundreds of rows, a web search yielding multiple lengthy articles, or verbose logging from a code executor can rapidly bloat the context window, diminishing reasoning quality even before the token limit is reached. The decision of what to include verbatim, what to condense into key facts, and what to omit entirely is a deliberate design choice, not a passive default. For instance, an agent tasked with summarizing a lengthy legal document might only require the core arguments and key findings, not the entire text of every cited case. Compression strategies, applied proactively, ensure that only the most pertinent information occupies valuable token space.
The Impact of Structural Placement
The position of information within the context window significantly influences its utilization by the model. Research has indicated a phenomenon known as the "lost in the middle" effect, where content positioned at the beginning and end of long contexts receives more attention from the model than information placed in the middle. Consequently, critical instructions, hard constraints, and task-essential directives should ideally occupy the initial segments of the context window. Retrieved information that is directly relevant to the current task should be placed towards the end, immediately preceding the user’s current query or task description. This arrangement maximizes the likelihood that the model will effectively leverage the contextual data to inform its response.
Managing Conversation History
Conversation history is often the fastest-growing component of an agent’s context. For long-running agents, retaining the entire history in every call leads to increased computational costs and decreased reliability with each subsequent inference. Effective context engineering necessitates a compression strategy—such as a rolling window, hierarchical summarization, or structured state extraction—applied at regular intervals, rather than waiting for the window to overflow. This ensures that the agent retains a meaningful representation of past interactions without overwhelming its immediate processing capacity.
Memory Engineering: Architecting Persistent Knowledge Systems
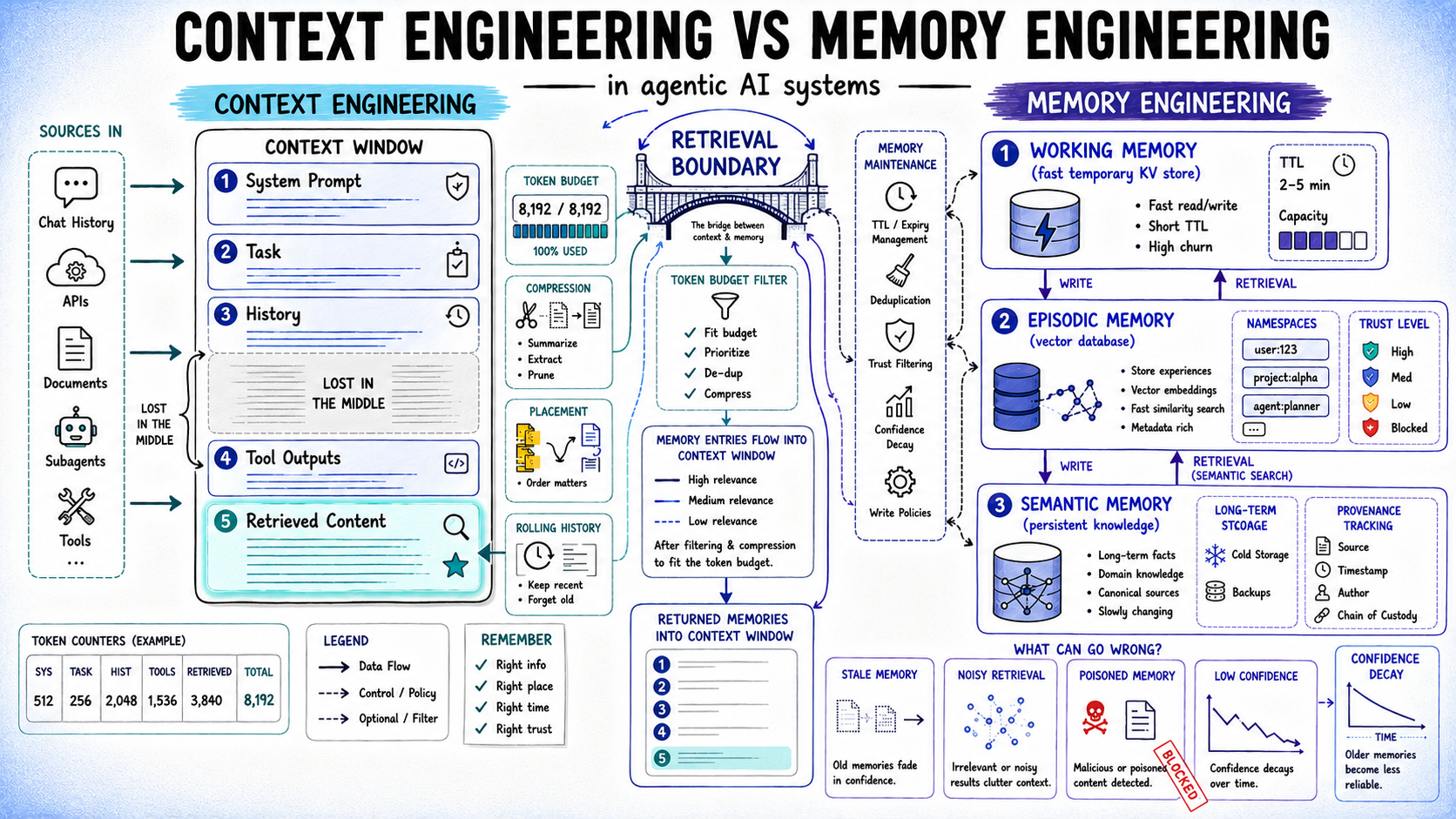
Once an inference call concludes, memory engineering takes over, determining what information warrants long-term retention and under what conditions it can be re-accessed. This involves four key considerations: what to write, where to store it, how to retrieve it, and how to maintain its accuracy over time.
The Strategic Importance of Write Policies
The design of write policies is a frequently underestimated yet critical aspect of memory engineering, profoundly impacting memory quality. While retrieval systems often garner the most attention, their efficacy is ultimately dictated by the quality and relevance of the data initially committed to the memory store. A well-defined write policy specifies:
- What constitutes a valuable memory: Criteria for identifying and prioritizing information that is likely to be useful in the future.
- When to write: Triggers for storing information, such as after a successful task completion, a significant user interaction, or when a certain confidence threshold is met.
- How to format memories: Structuring data in a way that facilitates efficient retrieval and interpretation, potentially including metadata like source, timestamp, and relevance score.
- Policies for overwriting and updating: Mechanisms for handling conflicting or evolving information to ensure memory accuracy.
Without explicit write policies, systems often default to storing excessive amounts of data, assigning equal trust to all entries, and retaining information indefinitely. This leads to an accumulation of low-value and outdated memories, a decline in the signal-to-noise ratio, and degraded retrieval quality. The outcome is a memory system that grows relentlessly while becoming progressively less useful.
Strategic Storage Layer Selection
Different types of memory serve distinct purposes and necessitate varied storage backends, which in turn influence available retrieval strategies.
| Memory Type | What it Stores | Storage Backend | Retrieval Method |
|---|---|---|---|
| Working | Active task state, intermediate results | In-memory or short-lived K/V (Redis) | Direct key lookup |
| Episodic | Past interactions, task runs, decisions | Vector store (Pinecone, Weaviate) | Semantic similarity search |
| Semantic | Persistent facts, user preferences, domain knowledge | Vector store + K/V hybrid | Semantic search or exact key |
| Procedural | Learned workflows, successful action patterns | Structured store or prompt injection | Pattern match, direct retrieval |
OpenAI’s context personalization cookbook distinguishes between retrieval-based memory and state-based memory for continuity-dependent use cases. Retrieval-based memory treats past interactions as loosely related documents, which can be fragile to phrasing variations and conflicting updates. Structured state extraction, wherein typed and validated facts are stored rather than raw conversation chunks, yields more consistent results for facts that require reliable application across sessions.
Sophisticated Retrieval Strategies
Retrieving information from memory is not a monolithic operation. A well-designed retrieval layer first checks working memory for fast, cheap, exact key lookups. If no relevant information is found, it falls back to semantic search in episodic or semantic memory. Crucially, it applies metadata filters for recency and trust levels before returning results, ensuring that only the most pertinent and reliable information is provided for the current step.
Proactive Memory Maintenance
A memory store lacking a maintenance policy will inevitably degrade over time. Entries accumulate, stale facts compete with current ones, and retrieval quality suffers as the signal-to-noise ratio diminishes. Essential maintenance routines include: confidence decay for volatile facts, deduplication of semantically similar entries, Time-To-Live (TTL) based expiry for working memory and time-sensitive data, and periodic compression of old episodic records into session-level summaries.
A MemoryEntry schema that directly encodes these concerns simplifies write and maintenance logic:
class MemoryEntry(BaseModel):
content: str
memory_type: str # working | episodic | semantic | procedural
importance: float # 0.0-1.0, gates long-term storage
confidence: float # decays over time for volatile facts
trust_level: float # 1.0 internal system, 0.5 user input, 0.0 external
created_at: datetime
expires_at: datetime | None
provenance: dict # agent_id, tool_name, session_id, input_hash
def should_write_to_long_term(entry: MemoryEntry) -> bool:
return (
entry.importance >= 0.6
and entry.confidence >= 0.7
and entry.trust_level >= 0.5
)The Retrieval Boundary: The Nexus of Memory and Context
Memory and context engineering are often discussed as separate disciplines, but their practical application reveals a deep interdependence. Both aim to ensure that an AI model has access to the correct information at the opportune moment. Memory systems generate candidate information, and context assembly then makes critical decisions about its ultimate inclusion.
At a high level:
- Memory systems identify and retrieve potential information relevant to the current task.
- Context assembly filters, ranks, and prioritizes this retrieved information based on current needs and available space.
The successful management of this boundary is what transforms a collection of disparate memory components into a coherent and functional agent system.
Failure Mode 1: Retrieval Without Contextual Constraints
A common failure occurs when retrieval is treated as an isolated process, disconnected from context assembly. A memory search might return numerous relevant entries, which are then unthinkingly injected into the prompt. As more memories are added, the context window gradually fills with retrieved content, leaving insufficient room for essential instructions, tool outputs, reasoning traces, and task-specific details.
The resulting symptoms can be misleading: the agent might appear to misunderstand instructions or fail to execute tasks correctly, even though the memory system accurately identified relevant information. The failure, in these instances, stems from the context assembly’s lack of a budgeting mechanism. A more effective approach involves retrieval-aware context assembly, where the context layer pre-allocates a token budget before retrieval commences. The retrieval layer then returns only the highest-value memories that can fit within this allocated budget.
async def retrieve_for_step(
self,
step: AgentStep,
max_tokens: int
) -> str:
candidates = await self.memory.search(
query=step.retrieval_query,
max_results=10,
filters=
"trust_level": "gte": 0.5,
"expires_at": "gt": datetime.now()
)
selected = []
used = 0
for entry in sorted(
candidates,
key=lambda e: e.relevance_score,
reverse=True
):
cost = self.token_count(entry.content)
if used + cost > max_tokens:
break
selected.append(entry.content)
used += cost
return "nn".join(selected)This code snippet illustrates how retrieval must operate within predefined context limits, not assume unlimited downstream space.
Failure Mode 2: Suboptimal Placement of Retrieved Information
Even when retrieval is successful and adheres to budget constraints, incorrect placement within the context window can render the information ineffective. A common oversight is treating retrieval solely as a search problem, neglecting its role in the current reasoning step. Retrieved memories might be appended arbitrarily, without considering their strategic importance.
This issue is particularly pronounced in long contexts, where attention is not uniformly distributed. Information embedded deep within a lengthy prompt can receive significantly less influence than information positioned near the beginning or end. This leads to a subtle failure: the retrieval was successful, but the placement undermined its impact. Effective context assembly must therefore optimize both retrieval and placement, ensuring that critical retrieved information is positioned strategically within the active reasoning region, rather than being appended as an afterthought.
Retrieval as an Integral Step in Context Construction
Ultimately, retrieval serves as the initial phase in transforming stored memory into usable context. The objective extends beyond merely retrieving relevant information; it involves ensuring that the retrieved data is indeed the right information for the current step, that its volume is appropriate for the context budget, and that its placement within the window allows the model to utilize it effectively.
When memory and context engineering are viewed as a unified retrieval-to-context pipeline, rather than isolated components, agent systems demonstrate enhanced reliability, efficiency, and scalability. Resources like the Weaviate blog on context engineering offer valuable insights into this integrated approach.
Conclusion: A Synergistic Approach to Agentic Intelligence
Context and memory engineering represent two crucial layers within a single overarching system that governs an AI model’s knowledge, its temporal access to that knowledge, and its subsequent utilization. Context engineering operates at the point of inference, meticulously shaping the active information window. Memory engineering functions across time, dictating what information is retained and how it can be accessed later.
| Dimension | Context Engineering | Memory Engineering |
|---|---|---|
| Core Question | What should the model see now, and how? | What should the system retain, and for how long? |
| Primary Artifact | Assembled context window per inference call | Persisted memory entries across calls and sessions |
| Token Management | Budget allocation per window component | Storage cost per entry type; retrieval cost per query |
| Compression | Tool outputs summarized before injection; history rolled or extracted | Old episodic records compressed; stale facts decayed or pruned |
| Freshness | Rolling history window; stale turns dropped | TTL on volatile facts; confidence decay over time |
| Trust | Source hierarchy governs assembly order | Provenance tracked per entry; low-trust content sanitized before write |
| Multi-Agent | Each agent assembles its own window independently | Scoped namespaces per agent; shared namespace for cross-agent facts |
| Failure Mode | Overflow, attention degradation, noisy assembly | Poisoning, staleness, retrieval miss, unbounded growth |
| Maintenance | Proactive compression at defined intervals | TTL expiry, deduplication, confidence decay, episodic archiving |
| Meeting Point | Retrieved memory enters context: budget and placement govern how | Context assembly requests retrieval within a token budget constraint |
In essence, an agentic system’s success hinges on the alignment of these two layers. Memory engineering determines what information is available, while context engineering determines which of that available information becomes actionable. This synergistic approach is fundamental to building AI agents that are not only intelligent but also consistently reliable and scalable in real-world applications.




{kind=link}