
The Paradigm Shift: Why Flexible Command-Line Interfaces Are Outpacing Dedicated MCP Servers for LLM Agents
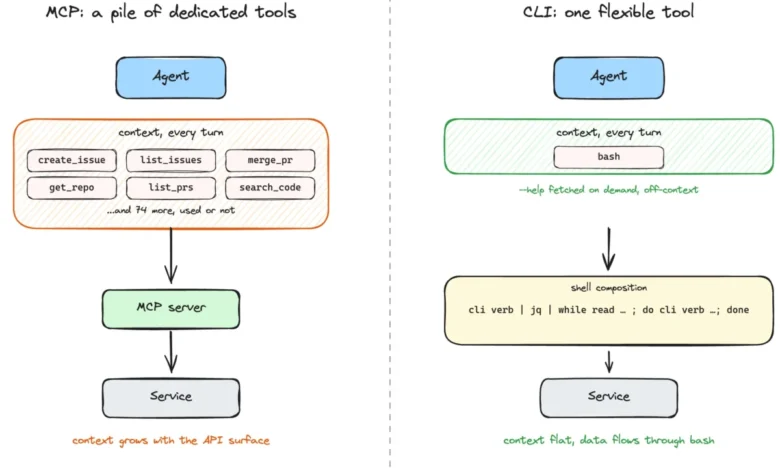
The landscape of integrating Large Language Model (LLM) agents with complex systems is undergoing a significant transformation, moving away from the once-dominant model of dedicated servers offering a predefined set of tools towards a more flexible and powerful approach centered on command-line interfaces (CLIs). As of the early months of 2026, the prevailing method for enabling an LLM agent to interact with systems like GitHub, Jira, Slack, Linear, PostgreSQL, and Neo4j involved deploying a Managed Control Plane (MCP) server. These MCP servers typically expose a curated collection of specific tools, such as create_issue, list_pull_requests, merge_pull_request, get_repository, and search_code. While this offered a seemingly streamlined onboarding experience, a growing realization has emerged: for a substantial number of real-world workloads, this "one-tool-per-operation" design is fundamentally misaligned with the evolving capabilities of modern LLMs.
The core thesis driving this shift is straightforward: while MCP designs often encapsulate each service as a bundle of discrete, specialized tools, a command-line interface presents the LLM agent with a single, highly adaptable instrument. With the current generation of LLMs, this flexible instrument is proving to be the superior choice. This evolution represents a fundamental change in how we conceptualize agent-system interaction, moving from a prescriptive menu-driven approach to a more dynamic, composable paradigm.
The Evolution of LLM Agent Interaction
Historically, the development of LLM agents for system interaction was a cautious endeavor. Early models, prone to hallucination, losing context in extended operations, and misinterpreting documentation, necessitated a defensive strategy. Wrapping every conceivable operation within a pre-baked, narrowly defined tool was a sensible safeguard. This approach minimized the burden on the LLM, which only needed to select the correct tool from a presented list. The complexity of executing multi-step processes or handling nuanced data manipulation was effectively abstracted away by the MCP server.
However, the capabilities of LLMs have advanced at an unprecedented pace. Today’s models are demonstrably more adept at understanding and executing complex instructions. They can effectively parse --help pages and SKILL.md documentation, leverage their training data to recognize canonical CLIs, and construct sequences of shell commands, such as bash scripts, with remarkable autonomy. Furthermore, their improved error handling allows them to retry operations with corrected flags, mitigating many of the issues that previously necessitated the granular tool approach. Consequently, the former "hard part" of complex execution has become significantly easier, while the previously "easy part" of tool selection has become less critical. The extensive descriptions and definitions of numerous narrow tools, once essential for guiding the LLM, now largely contribute to bloating the model’s context window without providing proportional benefit.
This shift is not without its challenges. Granting an LLM agent direct access to a terminal introduces a significantly amplified "blast radius." The very flexibility that enables an agent to ingeniously chain commands like gh | jq | xargs to achieve a desired outcome also opens the door to more insidious prompt injection attacks, potentially leading to actions far more detrimental than a misplaced database query. Therefore, a critical trade-off emerges: the increased power and flexibility of CLI access necessitate a more rigorous and thoughtful approach to security. This involves implementing robust sandboxing environments, establishing allowlists for permitted commands, running the agent under a dedicated, least-privilege operating system user, and configuring read-only roles for database access, among other standard security practices. Despite these considerations, the article argues that when terminal access can be secured appropriately, the advantages of the flexible CLI approach demonstrably outweigh the risks.

The Ubiquity of the "Pile of Tools" Pattern
The pattern of encapsulating a service as a collection of dedicated tools, as seen in MCP implementations, is not confined to a single domain. This approach is mirrored across various technologies. For instance, PostgreSQL offers MCPs alongside its native psql command-line client. Kubernetes, similarly, has its MCP equivalents to the powerful kubectl CLI. Even fundamental filesystem operations, such as listing files, reading content, moving data, and searching text, are often exposed as separate tools within an MCP framework, whereas the CLI paradigm relies on chaining commands like cat, ls, mv, and grep with pipes. The underlying instinct to break down complex operations into discrete, manageable units is consistent, and the CLI provides a powerful alternative to this granular decomposition. Crucially, the article emphasizes that the MCP specification itself does not mandate this proliferation of narrow tools; it primarily requires typed tool schemas. Implementations have historically gravitated towards numerous small, specialized tools due to established practices and API designs. However, the potential exists to develop flexible tools that accept a single, expressive input, allowing the LLM agent to shape its interaction more dynamically. This flexibility is increasingly becoming the preferred approach.
A Concrete Comparison: Neo4j MCP vs. Neo4j CLI
To illustrate these concepts, a comparative analysis is presented using the Neo4j MCP server and the Neo4j CLI (neo4j.sh). The Neo4j MCP server, designed to expose Neo4j functionalities to agents, offers a set of dedicated tools, including read query, write query, and schema retrieval. In contrast, neo4j.sh is a single binary that operates from the terminal, supporting credential profiles for multiple database connections. For a fair comparison, the analysis focuses on equivalent operations: querying data and retrieving schema information. The core operations and the underlying Cypher queries remain identical; the divergence lies solely in the mechanism of interaction – whether through a typed tool schema or a string command passed to a shell.
Querying Across Multiple Environments
A significant challenge arises when an LLM agent needs to interact with multiple instances of the same service, such as different database environments (development, staging, production). With MCP, the number of tools presented to the LLM grows not only with the features of the service but also with each additional environment. Consider an agent tasked with retrieving node counts from development, staging, and production Neo4j instances. Using MCP, a separate neo4j-mcp-server would be deployed for each environment. Consequently, the LLM’s context window would be burdened with the tool schemas from each server on every turn. For three databases, this would translate to twelve distinct schemas (four per server) before any actual work is performed by the agent.
The CLI approach offers a far more efficient alternative. The same task can be accomplished with a simple for loop in the shell:
$ for c in dev staging prod-ro; do
neo4j-cli query -c $c --format toon
"MATCH (n) RETURN count(n) AS nodes"
doneThis command utilizes a single binary, three credential profiles, and incurs zero per-turn context cost for the LLM. Adding a fourth environment simply requires adding another credential profile, rather than deploying an entirely new MCP server and its associated schemas. This efficiency extends to various workflows involving interaction with multiple similar entities, such as taking snapshots of production databases before a deployment, comparing schemas between staging and production environments, or executing health checks across all known databases.
Chaining Queries for Complex Analysis
Another critical scenario is the chaining of queries, where the output of one query serves as the input for another. For example, an agent investigating a fraudulent account might need to identify all accounts it has transacted with, and then determine which of those counterparties have the most frequent transactions with other accounts. This involves two sequential queries against the same database.

Within an MCP framework, the LLM must orchestrate this chaining. It would first execute a read-cypher tool, receiving a list of counterparty IDs. This list then resides in the LLM’s context window. Subsequently, the LLM must format these IDs as parameters for a second read-cypher call. The intermediate list of 80 counterparty IDs, for instance, occupies valuable context space, incurring token costs for the agent with each additional ID, irrespective of whether the agent needs to re-examine them.
The CLI, however, facilitates this chaining through a literal pipe (|):
$ neo4j-cli query -c prod-ro --format json
--param "seed=acct_19f3"
"MATCH (:Account id: $seed)-[:TRANSACTED]-(c:Account)
WHERE c.id <> $seed
RETURN collect(DISTINCT c.id) AS counterparties"
| neo4j-cli query -c prod-ro --params-from-stdin
"MATCH (a:Account)-[:TRANSACTED]-(b:Account)
WHERE a.id IN $counterparties
AND NOT b.id IN $counterparties + ['acct_19f3']
RETURN b.id, count(DISTINCT a) AS edges_into_cluster
ORDER BY edges_into_cluster DESC LIMIT 20"The --params-from-stdin option enables the second query to ingest the JSON output of the preceding query as parameters. Crucially, the list of counterparties never enters the LLM’s context window. The agent’s token expenditure remains constant, whether the intermediate cluster contains 5 or 500 counterparties. This demonstrates how the shell transcends its role as a mere execution environment; it becomes a powerful composition engine. The agent is no longer simply selecting operations from a menu but is actively constructing pipelines, with intermediate data flowing efficiently without taxing the LLM’s context. A two-step query becomes a pipe, a fan-out operation transforms into a for loop, and cross-database joins are managed through piped queries. Each of these would necessitate multiple MCP round-trips, with intermediate results being processed through the LLM’s context, potentially consuming more tokens on data shuffling than on intelligent analysis.
Interoperability Across Multiple CLIs
The principle of efficient data flow through shell pipelines extends to orchestrating interactions across diverse command-line tools, a common requirement in complex workflows. Imagine the task of migrating recent GitHub issues into a Neo4j database, creating :Issue nodes for each ticket, :User nodes for authors, and :TAGGED relationships for labels. The data originates from the GitHub CLI (gh), requires transformation (handled by jq), and is ultimately ingested by the Neo4j CLI (neo4j-cli).
In an MCP-based approach, this would involve multiple interactions. The agent would query the GitHub MCP server for the issue list. The entirety of each issue’s body would then be loaded into the LLM’s context. The LLM would parse out the necessary fields and then invoke a write-cypher tool for each issue. This translates to hundreds of round-trips through the LLM, with each issue’s full content residing in the conversation history.
The CLI approach, conversely, chains these three distinct tools in a single pipeline:

$ gh issue list --repo neo4j/neo4j --limit 100
--json number,title,author,labels
| jq -c '.[]'
| while read issue; do
neo4j-cli query --rw -c prod
--param "data=$issue"
"WITH apoc.convert.fromJsonMap($data) AS i
MERGE (n:Issue number: i.number) SET n.title = i.title
MERGE (u:User login: i.author.login)
MERGE (u)-[:OPENED]->(n)
FOREACH (label IN i.labels |
MERGE (l:Label name: label.name)
MERGE (n)-[:TAGGED]->(l))"
doneHere, gh retrieves the issues, jq formats each issue into a single JSON line, and a while loop passes each line to neo4j-cli as a Cypher parameter. The LLM’s role is reduced to generating this script once. The data then flows seamlessly through bash, bypassing the LLM’s context entirely. Whether dealing with a hundred issues or ten thousand, the LLM’s token cost remains constant. This pattern is highly adaptable. The gh command can be substituted with other CLIs that output JSON, such as jira issue list, linear, or even curl calls to webhooks. Similarly, the Cypher transformation can be replaced with any data processing logic for different databases. Unlike MCP tools, which are isolated, multiple CLIs can be chained together, enabling complex data pipelines that involve numerous distinct services and transformations.
The Double-Edged Sword of Terminal Control
The terminal, as a conduit for LLM agent interaction, offers unparalleled flexibility precisely because it is not a fixed interface but a composable environment that integrates with all other tools on a system. This inherent power, however, is also its primary vulnerability. A highly flexible tool, when misused, can inflict extensive damage. The increased access afforded by terminal control brings with it a commensurate responsibility. Robust security measures are paramount: sandboxing the shell environment, strictly defining allowlists for permissible commands, executing the LLM agent under a dedicated, least-privilege operating system user, and meticulously binding credentials to roles that inherently restrict destructive actions. These are not novel security paradigms but rather established system administration best practices applied to the context of an LLM that can execute commands at high speed. For environments where such stringent security measures cannot be implemented, an MCP server with a limited, fixed operational surface remains a viable option, providing a protocol-level guarantee against potentially harmful actions, such as the unauthorized access to sensitive files.
The overarching principle remains consistent: the advantage of the CLI lies not in the inherent superiority of shell scripting itself, but in its capacity for flexible input and composition. Features like pipes, variable substitution, and looping enable agents to construct complex operations dynamically. The most effective MCP servers of the future will likely adopt this philosophy, offering fewer, more expressive tools that accept dynamic inputs, thereby empowering the LLM agent to perform the composition rather than requiring developers to anticipate and pre-program every possible combination. Many current MCP servers reflect the underlying API’s structure rather than an LLM-centric design. Those that endure and excel will be the ones that intentionally embrace a smaller, more expressive interface, designed to facilitate sophisticated agent-driven workflows.





{kind=link}