
Navigating the Complex Landscape of Large Language Model Engineering: A Comprehensive Guide
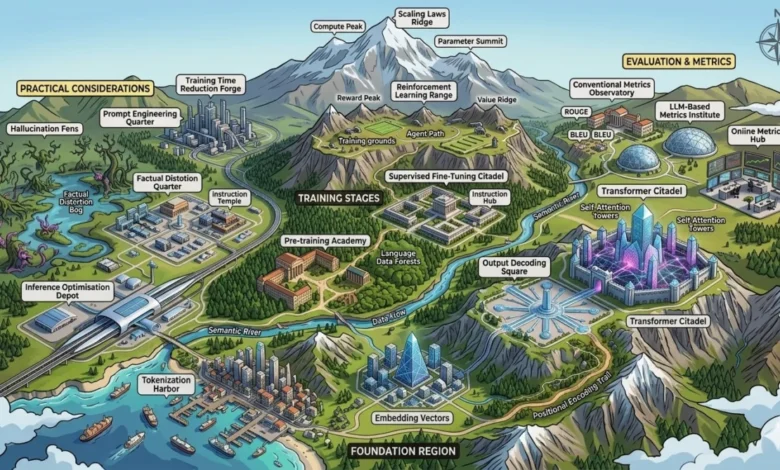
Large Language Models (LLMs) have rapidly ascended to become the bedrock of modern artificial intelligence, powering a vast array of applications from sophisticated chatbots and AI copilots to advancements in search, coding assistance, and automation. However, for engineers transitioning into this dynamic field, the learning curve can appear steep and fragmented. Concepts such as tokenization, attention mechanisms, fine-tuning, and evaluation are frequently presented in isolation, hindering the development of a cohesive mental model of how these elements interrelate. This article aims to demystify this complex ecosystem, offering a structured overview for practitioners seeking to design, train, and deploy robust LLM systems.
The journey into LLM engineering often involves grappling with a confluence of theoretical underpinnings and practical realities. Engineers, particularly those like the author transitioning from domains such as computer vision, must rapidly assimilate not only the theoretical foundations of transformer architectures but also the intricate trade-offs inherent in training, the bottlenecks encountered during inference, the persistent challenges of model alignment, and the pitfalls associated with robust evaluation. This guide endeavors to bridge this knowledge gap by providing a panoramic view of the LLM engineering landscape, moving systematically from the fundamental representation of text through model architectures, training methodologies, inference optimization, evaluation frameworks, and crucial practical considerations like prompt engineering and hallucination mitigation. The ultimate goal is to equip readers with a clear mental framework for comprehending the construction of contemporary LLM systems and the practical integration of each conceptual component.
From Textual Symbols to Numerical Representations
At the core of LLM functionality lies the transformation of human language into a format that computational models can process. This initial step involves converting discrete textual elements into numerical representations.
Tokenization: The Art of Subword Segmentation
The intuitive approach of assigning a unique numerical identifier to every word in a language quickly becomes impractical due to the sheer scale of vocabulary. English alone contains hundreds of thousands of words, rendering training on such an expansive lexicon computationally infeasible in terms of memory and efficiency. Conversely, encoding at the character level, while reducing the number of distinct units, presents its own set of challenges. Models would struggle to infer meaning from individual characters, and sequences would become excessively long, complicating the training process.
The solution lies in tokenization, a sophisticated method that segments text into subword units. These subwords, chosen for their frequency and utility, form the building blocks of the model’s vocabulary. Common words are represented as single tokens, while rarer words can be decomposed into combinations of smaller subwords. A widely adopted algorithm for this process is Byte-Pair Encoding (BPE). BPE begins with individual characters as initial tokens and iteratively merges the most frequent adjacent token pairs, gradually constructing a vocabulary of subword units until a predetermined vocabulary size is achieved. Each token within this vocabulary is then assigned a unique numerical identifier, or token ID.

Embeddings: Infusing Semantic Meaning
Following tokenization and the assignment of token IDs, the next critical step is to imbue these numerical representations with semantic meaning. This is achieved through text embeddings, which map discrete token IDs into continuous vector spaces. Within this high-dimensional space, tokens with similar meanings are positioned in close proximity, enabling the capture of nuanced semantic relationships. For instance, vector arithmetic can reveal analogies, such as the relationship between "king," "queen," "man," and "woman."
Embedding layers are trained to accept token IDs as input and generate dense, low-dimensional vectors as output. These embeddings are optimized concurrently with the model’s primary training objective, typically next-token prediction. Over time, the model learns embeddings that encapsulate both syntactic and semantic information about words, subwords, or tokens. Prominent embedding models include word2vec, GloVe, and those integrated within architectures like BERT.
Positional Encoding: Restoring Sequential Context
A fundamental challenge with transformer architectures, which process data in parallel, is their inherent lack of awareness regarding the sequential nature of language. Word order is paramount in conveying meaning, and even tokens separated by considerable distance within a sentence can maintain strong relational dependencies. To address this, positional information is injected into each token embedding. This allows the model to comprehend both local word order and long-range dependencies.
Several approaches exist for incorporating positional information:
- Absolute Positional Encodings: These are typically fixed sinusoidal functions or learned embeddings that are added to the token embeddings, explicitly encoding the position of each token within the sequence.
- Relative Positional Encodings: Instead of absolute positions, these methods encode the relative distance between tokens, which can offer greater flexibility and generalization, particularly for longer sequences.
- Rotary Positional Embeddings (RoPE): A more recent and effective technique that injects relative positional information by rotating embeddings based on their position, enhancing performance in capturing long-range dependencies.
The Transformer Architecture: A Paradigm Shift in Sequence Processing
Once text is tokenized, embedded, and enriched with positional encodings, it is fed into the model. The current state-of-the-art architecture for processing textual data is the transformer, which fundamentally relies on the attention mechanism. A typical transformer comprises a stack of transformer blocks, each consisting of distinct sub-layers.
Attention: The Core of Contextual Understanding
Introduced in the seminal paper "Attention Is All You Need," the attention mechanism revolutionizes how models process sequential data. In this framework, each token is projected into three distinct vectors: a query (representing what the token is looking for), a key (representing what the token offers), and a value (representing the actual information the token carries). Attention operates by comparing queries to keys through similarity scores, thereby determining how much of each token’s value should be aggregated. This dynamic process allows the model to selectively incorporate relevant context based on content, rather than solely on positional proximity.

Multi-head attention enhances this capability by running multiple attention mechanisms in parallel. Each "head" learns its own distinct projections, enabling the model to focus on different types of relationships simultaneously, such as syntactic structures, coreferences, or semantic nuances. The combined output of these heads provides a richer and more nuanced understanding than a single attention pass.
Various forms of the attention mechanism exist, tailored to specific purposes:
- Self-Attention: Allows tokens within the same sequence to attend to each other, capturing intra-sequence dependencies.
- Masked Self-Attention: Used in decoder architectures, this variant prevents tokens from attending to future tokens in the sequence, ensuring that predictions are made based only on preceding information.
- Cross-Attention: Enables tokens in one sequence (e.g., decoder) to attend to tokens in another sequence (e.g., encoder), facilitating tasks like machine translation.
A significant limitation of standard attention is its quadratic complexity (O(n²)) with respect to sequence length. As sequences grow longer, computational and memory demands escalate rapidly, making processing extended contexts prohibitively expensive and slow. This quadratic scaling represents a primary bottleneck in scaling LLMs and is a vigorous area of research, with efforts focused on developing selective attention mechanisms that judiciously choose which tokens attend to others.
Architecture Types: Tailoring for Tasks
LLM tasks are typically built using one of the following core transformer architectures:
- Encoder-Decoder Architectures: These models, exemplified by the original Transformer, consist of an encoder that processes the input sequence and a decoder that generates the output sequence. They are well-suited for sequence-to-sequence tasks like machine translation and summarization.
- Decoder-Only Architectures: Models like the GPT series utilize only the decoder component of the transformer. They are autoregressive, generating output token by token, making them ideal for generative tasks such as text completion and creative writing.
- Encoder-Only Architectures: Models such as BERT employ only the encoder. They are adept at understanding and representing input sequences, making them suitable for tasks like text classification, sentiment analysis, and question answering where the output is a representation of the input.
Next Token Prediction and Output Decoding
LLMs are fundamentally trained to predict the next token in a sequence. This is achieved by outputting a probability distribution over the entire vocabulary. The raw output, known as logits, is then passed through a softmax function to yield probabilities for each potential next token.
The most straightforward decoding strategy is greedy decoding, where the token with the highest probability is always selected. However, this approach can be suboptimal, as the locally most probable token may not lead to the most coherent or natural overall sequence.

To enhance generation quality and diversity, models can sample from the probability distribution. This allows for exploration of various continuations. Furthermore, the generation process can be branched by considering multiple candidate tokens and expanding them in parallel.
Several popular decoding strategies are employed in practice:
- Greedy Decoding: Selects the token with the highest probability at each step.
- Beam Search: Explores multiple candidate sequences in parallel, keeping track of the "beam" of most likely sequences and expanding them. This generally yields more coherent outputs than greedy decoding but can be computationally intensive.
- Sampling-based Methods (Top-K, Nucleus Sampling): These methods introduce randomness by sampling from a subset of the most probable tokens. Top-K sampling considers the top K most probable tokens, while Nucleus sampling considers tokens whose cumulative probability exceeds a certain threshold. These methods offer a balance between coherence and diversity.
The temperature parameter plays a crucial role in controlling the "flatness" or "peakiness" of the probability distribution. A low temperature (e.g., <1) makes the model more deterministic, concentrating probability mass on the most likely tokens, leading to more focused and predictable output. A high temperature (>1) flattens the distribution, increasing randomness and diversity, which can be useful for creative generation but may also lead to less coherent results.
The Multi-Stage Journey of LLM Training
The development of LLMs typically involves a multi-stage training process, moving from broad language understanding to task-specific adaptation and refinement.
Pre-training: Laying the Foundation of Language Understanding
Pre-training is the most computationally intensive phase, where LLMs acquire general language patterns, grammar, syntax, and semantic understanding from massive, diverse datasets. These datasets, often comprising hundreds of billions to trillions of tokens, are sourced from a wide array of materials, including web pages, books, articles, code repositories, and conversational logs.
Researchers leverage LLM scaling laws to guide decisions regarding model size, training duration, and dataset scale. These laws empirically describe the relationship between these factors and model performance, enabling more efficient resource allocation and optimal setup for achieving desired performance levels.

Crucially, data pre-processing is paramount during pre-training. Raw text, often riddled with inconsistencies, biases, and noise, can significantly degrade LLM performance if used directly. Datasets are meticulously cleaned and filtered to remove low-quality content, offensive material, and personally identifiable information. Challenges such as data imbalance across sources, multilingual content, and the presence of code or structured data require careful handling. Datasets are typically filtered by language and quality, and imbalances are addressed through techniques like data augmentation or re-weighting.
Supervised Fine-Tuning: Task Specialization
Following pre-training, supervised fine-tuning (SFT) adapts the model to perform specific tasks. Instead of retraining all parameters, a common practice is to keep the majority of pre-trained weights frozen and train only a small subset of additional parameters. This can be achieved by introducing lightweight adapter modules or employing parameter-efficient methods like LoRA (Low-Rank Adaptation). SFT utilizes a smaller, carefully curated dataset of high-quality, labeled examples relevant to the target task.
At a higher level, SFT is where the model learns desired behaviors for specific applications. This typically involves:
- Instruction Following: Training the model to understand and execute instructions provided in natural language.
- Domain Adaptation: Fine-tuning the model on data from a specific domain (e.g., medical, legal) to improve its expertise in that area.
- Style Transfer: Adapting the model’s output to match a particular writing style or tone.
These techniques collectively align the pre-trained model with the specific behaviors required at inference time.
Reinforcement Learning: Refining Behavior and Alignment
While SFT teaches the model what to do, reinforcement learning (RL) refines how well it performs, particularly in open-ended or subjective tasks like dialogue, reasoning, and ensuring safety. Unlike supervised learning with fixed targets, RL introduces a feedback loop: model outputs are evaluated, scored, and iteratively improved. This makes RL a vital tool for aligning models with human preferences, encouraging helpful, harmless, and honest behavior, reducing toxic or biased outputs, and enhancing conversational quality and instruction-following capabilities.
Because alignment data is generally smaller but of higher quality than pre-training data, RL acts as a fine-grained steering mechanism rather than a source of new knowledge. A common paradigm is Reinforcement Learning from Human Feedback (RLHF), which typically involves:

- Data Collection: Gathering human-annotated data to train a reward model that predicts human preferences.
- Reward Model Training: Training a separate model to predict the quality of LLM outputs based on human rankings.
- RL Fine-Tuning: Using the reward model as a guide to fine-tune the LLM through RL algorithms, optimizing its policy to generate outputs that maximize the predicted reward.
Optimizing the LLM policy in RL can be complex. Algorithms like Proximal Policy Optimization (PPO) and Trust Region Policy Optimization (TRPO) are employed to address challenges such as policy collapse and the destruction of learned knowledge. RL for language models can be categorized into online and offline approaches based on data collection and usage during training. Furthermore, reasoning-aware RL, such as rewarding intermediate reasoning steps in Chain-of-Thought (CoT) prompting, can improve structured and reliable problem-solving.
Mitigating Hallucinations in LLMs
A persistent challenge with LLMs is their tendency to produce hallucinations—non-factual completions that can sound plausible but are incorrect. This stems from their probabilistic nature; they predict the next token based on learned patterns and previously generated tokens, not necessarily on factual recall. Several strategies can mitigate this effect:
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) integrates external knowledge sources at inference time. The LLM retrieves relevant, factual information from a knowledge base and grounds its responses in verified data, reducing reliance on potentially outdated or incomplete internal knowledge. A RAG pipeline typically comprises:
- Document Indexing: Creating an index of external documents for efficient retrieval.
- Retriever: A component that searches the index to find relevant documents based on the user’s query.
- Generator: The LLM, which uses the retrieved information to formulate a response.
Training to Acknowledge Uncertainty
Explicitly training models to acknowledge uncertainty when insufficient information is available discourages the generation of speculative or incorrect statements. This involves teaching the model to respond with "I don’t know" or express its limitations.
Exact Matching and Post-Evaluation
Employing strict matching or verification against trusted sources or external model-based verifiers during or after generation ensures that the output aligns with factual references, especially for sensitive or precise information.
The Imperative of Optimization: Training and Inference
Optimizing LLMs is crucial for both their development and deployment, addressing resource constraints and ensuring efficient, high-quality user experiences.

Training Optimization
Training LLMs is a resource-intensive endeavor, requiring massive GPU clusters. Stochastic Gradient Descent (SGD) and its variants are commonly used, processing data in batches for stability and efficiency. For models exceeding single-GPU capacity, distributed training becomes essential, involving strategies such as:
- Data Parallelism: Replicating the model across multiple GPUs and distributing data batches.
- Model Parallelism: Splitting model parameters across GPUs.
- Pipeline Parallelism: Partitioning the model layers across GPUs, creating a pipeline for computation.
- Zero Redundancy Optimizer (ZeRO): A memory optimization technique that partitions optimizer states, gradients, and parameters across data-parallel processes.
Other techniques to reduce memory and accelerate training include gradient checkpointing, mixed-precision training, and efficient optimizer implementations.
Inference Optimization
Serving millions of requests efficiently requires significant inference optimization. Key techniques include:
- Quantization: Reducing the precision of model weights (e.g., from FP32 to FP16 or INT8) to decrease memory footprint and speed up computation.
- KV Caching: Storing the key and value states from previous attention computations to avoid redundant calculations during token generation.
- Model Pruning: Removing less important weights or neurons to reduce model size and computational cost.
- Knowledge Distillation: Training a smaller, faster "student" model to mimic the behavior of a larger, more capable "teacher" model.
- Optimized Kernels: Utilizing highly optimized software kernels (e.g., FlashAttention) for specific operations like attention computation.
- Batching: Grouping multiple inference requests together to improve GPU utilization.
Prompt Engineering: Guiding Model Behavior
Prompt engineering is a critical discipline in LLM usage, as a model’s behavior at inference time is profoundly influenced by how it is conditioned. The same model can yield dramatically different outputs based on the precise wording, context, and constraints embedded within a prompt. Prompt engineering is an iterative process, akin to software development, where small modifications can lead to significant shifts in output. Prompts should be treated as code, subjected to rigorous testing, measurement, refinement, and version control.
Elements of a Strong Prompt
Effective prompts typically exhibit several key characteristics:
- Clarity and Specificity: Clearly articulate the desired task, constraints, and format of the output.
- Contextual Information: Provide sufficient background information for the model to understand the request.
- Examples (Few-Shot Learning): Including a few examples of input-output pairs can guide the model towards the desired response pattern.
- Role-Playing: Assigning a persona to the model (e.g., "Act as a historian") can shape its tone and perspective.
- Step-by-Step Instructions: Breaking down complex tasks into sequential steps can improve performance.
Practical Considerations in Prompt Design
- Iterative Refinement: Start with a basic prompt and incrementally add complexity and specificity.
- Negative Constraints: Specify what the model should not do (e.g., "Do not include technical jargon").
- Output Formatting: Define the desired structure of the output (e.g., JSON, bullet points, paragraphs).
- Temperature and Sampling: Adjust decoding parameters to control the creativity and determinism of the output.
The Crucial Role of Evaluation
Evaluating LLMs is a multifaceted challenge, as their applications span a wide spectrum from structured question answering to open-ended generation. No single metric can comprehensively capture performance across all tasks. Evaluation strategies are highly problem-dependent, but generally fall into several categories, incorporating both traditional metrics and LLM-based evaluators.

The cornerstone of any evaluation is a robust evaluation dataset. This dataset must be diverse, clean, grounded in real-world scenarios, and aligned with the target tasks for the model.
Conventional Metrics
Traditional metrics, often based on word-level statistics, are simple to implement and fast. However, they have limitations, as they typically do not understand semantics or nuances in language. Examples include:
- Accuracy: For classification tasks.
- BLEU (Bilingual Evaluation Understudy): For machine translation, measuring n-gram overlap.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): For summarization, measuring overlap with reference summaries.
- F1 Score: A harmonic mean of precision and recall, often used in information retrieval and classification.
LLM-based Evaluation
Leveraging LLMs themselves as evaluators offers a more nuanced approach, capable of assessing aspects like coherence, relevance, and helpfulness.
- LLM-as-a-Judge: An LLM is prompted to evaluate the output of another LLM against predefined criteria. This can involve scoring responses, comparing multiple outputs, or performing classification tasks.
- Factuality and Groundedness: LLMs can be used to verify factual claims by cross-referencing with external knowledge sources.
- Toxicity and Bias Detection: LLMs can identify and flag harmful or biased content.
However, LLM-based evaluation is not foolproof and comes with its own quirks:
- Prompt Sensitivity: The evaluation results can be highly sensitive to the prompts used for the judge LLM.
- Bias in Judge LLM: The judge LLM itself may possess inherent biases that influence its evaluations.
- Cost and Latency: LLM-based evaluation can be more expensive and slower than traditional metrics.
- Reproducibility: Ensuring consistent and reproducible results can be challenging due to the probabilistic nature of LLMs.
Careful calibration, standardization of prompts, rigorous testing, and awareness of potential biases are essential for reliable LLM-based evaluation. Beyond these, specialized metrics exist for evaluating RAG pipelines and text summarization tasks.
When to Use LLM-as-a-Judge vs. Traditional Metrics
When evaluating subjective qualities like summarization quality, tone, helpfulness, or adherence to instructions, where rigid rules fall short, LLM-as-a-judge excels. It can assess responses against a rubric rather than relying on exact matches.

Conversely, traditional metrics remain indispensable when a clear ground truth exists, such as for factual accuracy or precise answer extraction. They offer speed, cost-effectiveness, and consistency.
The most effective approach often combines both: traditional metrics for objective correctness and LLM judges for subjective or open-ended quality assessment.
Evaluation Loops in Production
Effective evaluation extends into production, forming continuous evaluation loops:
- Offline Evaluation: Rigorous testing on curated datasets before deployment.
- Shadow Deployment: Running the new model alongside the existing one without user interaction to compare outputs.
- A/B Testing: Exposing different user segments to different model versions to measure performance differences in real-world scenarios.
- Continuous Monitoring: Logging user interactions, sampling them for review, and analyzing real-world performance to identify failure cases and usage pattern shifts.
As systems evolve, so does evaluation. Behavior drift, where model performance subtly degrades over time due to external factors, necessitates vigilant monitoring of both inputs and outputs to detect subtle shifts that could impact user experience.
Understanding LLM Criticisms
A common criticism leveled against LLMs is their tendency to act as "information averages." Instead of storing or retrieving discrete facts, they learn a smoothed statistical distribution over text. This means their outputs often reflect the most likely blend of many possible continuations, rather than a grounded, singular "true" statement. This can manifest as overly generic answers or confident-sounding statements that are merely high-probability linguistic patterns.
At the heart of this behavior is the cross-entropy objective, which trains models to minimize the discrepancy between predicted token probabilities and the observed next token in the training data. While effective for learning fluent language, cross-entropy rewards likelihood matching rather than truth, causality, or cross-contextual consistency. It cannot distinguish between "plausible wording" and "correct reasoning." This limitation leads to mode-averaging, where the model favors safe, central predictions over sharp, verifiable ones. Consequently, LLMs can excel at fluent synthesis but may struggle with tasks requiring precise symbolic reasoning, long-horizon consistency, or factual grounding without external systems like retrieval or verification.

Summary: A Symphony of Interdependent Systems
The creation and deployment of large language models is not a singular achievement but a testament to the intricate interplay of numerous interdependent systems. From the foundational stages of tokenization and embeddings, through the sophisticated attention-based architectures, to the multi-stage training paradigms of pre-training, fine-tuning, and reinforcement learning, each layer contributes a specific function in transforming raw text into capable and controllable models.
The complexity and excitement of LLM engineering lie in the fact that performance is rarely dictated by a single component. Efficiency innovations such as KV-caching, FlashAttention, and quantization are as vital as high-level design choices like model architecture or alignment strategy. Similarly, success in production hinges not only on training quality but also on inference optimization, evaluation rigor, adept prompt design, and continuous monitoring for drift and failure modes.
Viewed holistically, LLM systems are less akin to a monolithic model and more like an evolving stack: data pipelines, training objectives, retrieval systems, decoding strategies, and feedback loops all operate in concert. Engineers who cultivate a mental map of this stack can transcend mere "model usage" and embark on designing systems that are reliable, scalable, and aligned with real-world constraints.
As the field continues its rapid evolution—pursuing longer context windows, more efficient architectures, enhanced reasoning abilities, and tighter human alignment—the core challenge persists: bridging statistical learning with practical intelligence. Mastering this bridge is the defining characteristic of an LLM engineer.
Notable Models in Chronological Order
- BERT (2018)
- GPT-1 (2018)
- RoBERTa (2019)
- SpanBERT (2019)
- GPT-2 (2019)
- T5 (2019)
- GPT-3 (2020)
- Gopher (2021)
- Jurassic-1 (2021)
- Chinchilla (2022)
- LaMDA (2022)
- LLaMA (2023)
The development of these foundational models marks significant milestones in the progression of natural language processing, each introducing novel architectures, training methodologies, or scale that pushed the boundaries of what AI could achieve. The ongoing research and development in this area promise even more sophisticated and capable LLM systems in the future, continually reshaping the landscape of artificial intelligence.




{kind=link}