
The Unseen Costs: Navigating the Critical Trade-offs in Production AI Deployment
The landscape of Artificial Intelligence development often emphasizes the intricate process of building and refining models, focusing on achieving pinpoint accuracy. However, a critical gap exists in educational curricula: the complex decisions that immediately follow model creation and precede real-world deployment. Questions surrounding the optimal balance between automation and human oversight, the threshold for transitioning from prompt engineering to fine-tuning, and the financial implications of real-time versus batch inference are rarely addressed in academic settings, yet they become paramount within the first week of production. This article delves into six pivotal trade-offs encountered in production AI, drawing upon recent research to illuminate how organizations are navigating these common challenges. While definitive answers remain elusive, this analysis offers frameworks, quantitative insights, and contextual understanding to expedite future decision-making.
Index of Production AI Trade-offs
- Build vs. Buy in the LLM Era: When Calling an API Stops Making Sense
- Model Complexity vs. Maintainability: Who Debugs This in Six Months?
- Data Quantity vs. Data Quality: More Data Isn’t Always the Answer
- Throughput vs. Latency: Batch or Real-Time Inference
- Prompt Engineering vs. Fine-Tuning: Two Very Different Investment Curves
- Automation vs. Human Oversight: How Much Do You Trust the Model to Act Alone?
Sara Nóbrega, an educator specializing in AI empowerment through her platform "Learn AI," highlights the disparity between theoretical model building and practical deployment realities. "The focus is often on how to make a model accurate," Nóbrega observes. "What’s frequently overlooked are the immediate, high-stakes decisions that dictate its success or failure in the wild." These operational decisions, she asserts, are the true determinants of an AI system’s long-term viability and cost-effectiveness.
1. Build vs. Buy in the LLM Era: When Calling an API Stops Making Sense
The once-dominant question of whether to train an AI model from scratch has largely been settled; few organizations now embark on such resource-intensive endeavors. The contemporary challenge, particularly within the Large Language Model (LLM) ecosystem, presents a more nuanced decision tree with three primary paths: leveraging Application Programming Interfaces (APIs) from providers like OpenAI, fine-tuning existing open-source models, or developing and hosting a proprietary stack. Each option carries distinct cost structures and failure modes, demanding careful consideration as AI adoption scales.
In 2025, an Omdia survey encompassing 376 technical and business stakeholders revealed a near-universal consensus, with 95% agreeing that building offers superior customization and control. Simultaneously, 91% acknowledged that pre-built platforms facilitate faster deployment. This duality—enhanced control versus accelerated delivery—forms the crux of the dilemma.
The financial implications become starkly apparent at scale. For applications generating fewer than 100,000 daily requests, utilizing a service like GPT-4o Mini via API is typically the most pragmatic choice, offering low overhead and rapid iteration capabilities. However, as request volumes exceed one million daily, per-token costs begin to significantly impact profit margins. Research from 2025 by Ptolemay, analyzing the total cost of ownership for LLMs, indicates that hardware and electricity constitute only 20% to 30% of self-hosting expenses. The overwhelming majority, 70% to 80%, is attributed to staffing costs, a factor frequently underestimated in build-vs-buy analyses.

This oversight is compounded by studies showing that teams commonly exceed their LLM cost budgets by an average of 340%. A 2026 analysis by TianPan identified the primary drivers as the absence of per-tenant usage tracking and missing query-level cost attribution, rather than the base per-token rates themselves. Without visibility into which features or prompts are consuming the most resources, organizations struggle to implement effective cost controls.
Furthermore, the specter of framework lock-in looms large. The maintenance mode announcement for Hugging Face’s Text Generation Inference in late 2025 forced teams reliant on it to undertake costly migrations, whereas API users remained largely unaffected.
The practical framework for navigating this decision often hinges on projected scale and complexity:
- API Integration: Ideal for rapid prototyping, lower-volume applications, and when off-the-shelf capabilities suffice. Offers minimal operational burden and faster time-to-market.
- Fine-tuning Open-Source Models: A viable middle ground for applications requiring specialized knowledge or performance beyond standard APIs, but where full custom stack development is prohibitive. Demands greater engineering expertise and infrastructure management.
- Proprietary Stack Development: Suitable for highly specialized, large-scale applications demanding complete control over data, performance, and security. Carries the highest upfront investment and ongoing operational responsibility.
Organizations must meticulously project future demand and internal capabilities to avoid the pitfalls of underestimating the total cost of ownership, particularly the hidden expenses associated with engineering talent and infrastructure management.
2. Model Complexity vs. Maintainability: Who Debugs This in Six Months?
The introduction of the CACE (Changing Anything Changes Everything) principle in a seminal Google paper on machine learning systems underscores a fundamental challenge: the inherent interconnectedness and fragility of complex ML pipelines. While a simple linear regression model might tolerate minor adjustments with predictable outcomes, ensembles and neural networks are prone to unexpected cascading failures triggered by seemingly small modifications.
Research into ML technical debt reveals that data dependency poses a more significant challenge than code dependency. This is primarily because data is inherently more difficult to track, version, and explain to future teams inheriting the system. A comprehensive study by CMU MLIP highlights that the actual model code often represents a small fraction of a real-world ML system; the bulk comprises feature stores, pipeline logic, monitoring infrastructure, retraining triggers, and the intricate "glue" connecting these components.

The temptation to adopt more complex models for marginal accuracy gains—even as little as 2%—can lead to substantial long-term costs. Teams may find themselves dedicating 18 months or more to debugging, managing retraining overhead, and grappling with the "nobody remembers why we did this" tax. This refers to the accumulated institutional knowledge loss and the difficulty in understanding the rationale behind intricate model architectures.
Before deploying a complex model, the critical question to pose is: "Who will be responsible for maintaining this system in a year?" If the honest answer is uncertain, it signifies a potential point of failure and a robust argument for opting for a simpler, more manageable solution. The long-term cost of debugging and retraining a complex, poorly understood system can far outweigh the initial gains in accuracy.
Giving Your AI Unlimited Updated Context
A crucial element in maximizing AI utility is equipping it with dynamic, up-to-date information. Techniques like Retrieval Augmented Generation (RAG) enable AI models to access and incorporate external knowledge bases, overcoming the limitations of their static training data. This approach is vital for applications requiring current information, such as customer support chatbots, research assistants, or financial analysis tools. By providing AI with access to real-time data, organizations can ensure more accurate, relevant, and contextually aware responses, significantly enhancing the perceived value and effectiveness of AI deployments.
3. Data Quantity vs. Data Quality: More Data Isn’t Always the Answer
While the adage "more data is better" holds true for foundation models trained on internet-scale corpora, its applicability diminishes significantly in applied machine learning scenarios. Research indicates that beyond a certain "noise threshold," the introduction of low-quality data can either stagnate or actively degrade model performance. This phenomenon implies that the relationship between sample size and accuracy is not linear and breaks down when data integrity is compromised.
The "data swamp" problem is a common manifestation of this issue within organizations. The ease and low cost of data storage often lead teams to collect vast quantities of information with the assumption that it will prove useful at some future point. However, without robust data governance, this approach results in an unwieldy data pool that requires weeks of cleaning, inflates storage and pipeline costs, and slows down experimentation without yielding tangible improvements.
The medical AI field offers a clear illustration of this principle. Small, meticulously curated datasets with expert-verified labels have consistently outperformed larger datasets marred by unreliable annotations. In these instances, the model learns correct patterns more effectively from less data because the signal is clean and unambiguous.

A more practical guiding question for practitioners is: "How noisy is our current data, and what is the return on investment for one additional hour of data cleaning versus one additional day of data collection?" Prioritizing data quality over sheer quantity can lead to more efficient model development and superior performance, especially in domains where precision is paramount.
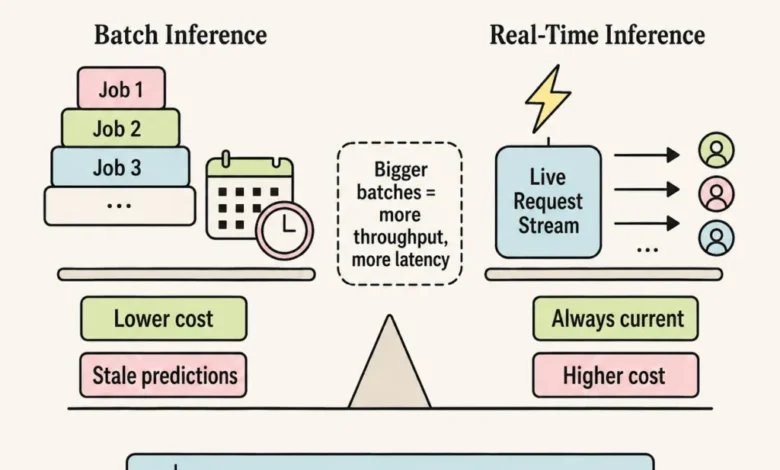
4. Throughput vs. Latency: Batch or Real-Time Inference
Batch and real-time inference represent fundamentally different system architectures, and selecting the incorrect approach can trigger a cascade of difficult-to-reverse infrastructure, cost, and user experience decisions.
Batch inference involves generating predictions on a predetermined schedule—hourly, daily, or weekly—which are then stored in a database for subsequent retrieval. This method offers lower operational costs, simpler infrastructure, and ease of debugging. However, the predictions generated may become stale between scheduled updates.
Real-time inference, conversely, provides on-demand predictions within milliseconds to seconds. While ensuring current data, it demands continuous uptime, leading to higher costs and more complex monitoring requirements.
The inherent tension lies in the trade-off between batch size and performance. Larger batch sizes in batch inference yield higher overall throughput but increase latency for individual requests. Real-time systems typically operate with a batch size of one, prioritizing speed at the potential expense of computational efficiency.
A common mistake is the default adoption of real-time inference simply because it sounds more sophisticated. However, most business problems do not necessitate sub-second prediction times. Applications like nightly churn score calculations, weekly recommendation refreshes, or daily fraud model updates are inherently batch-oriented and often over-engineered as real-time solutions, leading to significant cost discrepancies at scale.

A practical heuristic is: if users will not perceive a difference between a prediction that is five minutes old versus one that is five milliseconds old, batch inference is likely the more appropriate and cost-effective choice.
5. Prompt Engineering vs. Fine-Tuning: Two Very Different Investment Curves
The decision-making process regarding prompt engineering versus fine-tuning has become more refined in recent months, revealing distinct investment profiles and optimal use cases.
Prompt engineering is characterized by its speed, low cost, and flexibility. Iterations can range from hours to days, and it proves highly effective for a broad spectrum of tasks, particularly when leveraging advanced frontier models. The primary drawback is its inherent fragility; minor changes in input can lead to inconsistent outputs, and complex prompts with intricate formatting rules are susceptible to breaking under edge cases.
Fine-tuning, on the other hand, demands a substantial upfront investment in compute resources, data preparation, and engineering time. Once completed, it offers reliability and consistency at scale. A practical example cited involved fine-tuning GPT-4o for a customer support chatbot, incurring approximately $10,000 in compute costs and six weeks of data preparation. In contrast, a Retrieval Augmented Generation (RAG) alternative for the same task was deployed in just two weeks.
Current practitioner guidance suggests prioritizing prompt engineering as the initial approach. Fine-tuning should be reserved for scenarios where prompting fails to resolve critical issues. For applications with fewer than 100,000 queries, prompting is almost always the more judicious choice. Fine-tuning typically demonstrates its value at high volumes, particularly for stable and well-defined tasks.
A 2025 analysis indicated that prompt optimization techniques, such as those offered by DSPy, outperformed fine-tuning by 6 to 19 percentage points on certain benchmarks, utilizing significantly fewer rollouts. The gap between these methods appears to be narrowing annually. In many production stacks, fine-tuning is now viewed as a final step, implemented only after prompting has demonstrably reached its limitations.

A common hybrid pattern in production involves a model fine-tuned for domain-specific style and tone, augmented with RAG for factual grounding. This synergistic approach leverages the strengths of both techniques to address distinct aspects of AI performance.
6. Automation vs. Human Oversight: How Much Do You Trust the Model to Act Alone?
The pivotal question in production AI deployment is not merely whether to automate, but rather understanding the cost of an incorrect decision and who bears that responsibility. Human-in-the-loop (HITL) systems exist on a spectrum, from human review of every AI output to full automation with humans monitoring for anomalies. Most production systems operate in a hybrid model, routing low-confidence predictions to human reviewers while allowing high-confidence outputs to proceed automatically.
However, the operational cost of HITL is substantial. Reviewing every model decision is not scalable, and real-time human intervention can impede system speed. Furthermore, reviewer inconsistency can degrade the quality of labels used for future model improvements.
The prevailing operational pattern is selective HITL, where human review is triggered only for edge cases, low-confidence outputs, or high-stakes decisions. In regulated industries such as healthcare, finance, and legal, HITL is often a compliance requirement. For instance, a radiologist might review AI-flagged tumors, or a lawyer might scrutinize AI-identified contract clauses, situations where the cost of error is prohibitively high for full automation.
A framework for considering this split involves:
- Full Automation: Suitable for low-risk, high-volume tasks where occasional errors have minimal impact.
- Selective HITL: Ideal for tasks with moderate risk, where confidence scores can reliably flag potential issues for human review.
- Full HITL: Necessary for high-risk, high-impact decisions where compliance or significant financial/reputational damage necessitates human validation of every output.
The fundamental design question for any workflow is determining the precise point at which this line should be drawn, and crucially, whether the humans involved possess the clear authority to override the model when their judgment differs.

What to Take Away
If the six trade-offs discussed here could be distilled into a single guiding principle for production AI, it would be this: in the real world, the cost of a decision is rarely borne at the point where the decision is made. A more complex model incurs maintenance costs months down the line. A real-time system demands perpetual 24/7 infrastructure expenditure. Substandard data at scale translates to costly retraining cycles. A cleverly crafted prompt might lead to fragility under edge cases, and full automation carries the risk of irreversible damage when something goes wrong. The true challenge lies in accurately identifying where these costs will land and posing the right questions early enough to proactively manage them.
References
[1] Omdia, Navigating Build-Vs.-Buy Dynamics for Enterprise-Ready AI (2025).
[2] Ptolemay, LLM Total Cost of Ownership 2025: Build vs Buy Math (2025).
[3] TianPan, The Build-vs-Buy LLM Infrastructure Decision Most Teams Get Wrong (2026).
[4] D. Sculley et al., Hidden Technical Debt in Machine Learning Systems (2015), NeurIPS.
[5] CMU MLIP, Technical Debt — Machine Learning in Production (2024).
[6] Z. Qi et al., Impacts of Dirty Data: an Experimental Evaluation (2018).
[7] S. Sigari, Striking the Balance Between Data Quality and Quantity in Machine Learning (2023).
[8] C. Zhou, Batch Inference vs. Real-Time Inference: What, When, and Why (2025).
[9] S. Jolfaei, Fine-Tuning vs RAG vs Prompt Engineering: When to Use What (2025).
[10] LLM Stats, Is Fine-Tuning Better Than Prompt Engineering in 2026? (2026).
[11] A. Masood, Operationalizing Trust: Human-in-the-Loop AI at Enterprise Scale (2025).




{kind=link}