
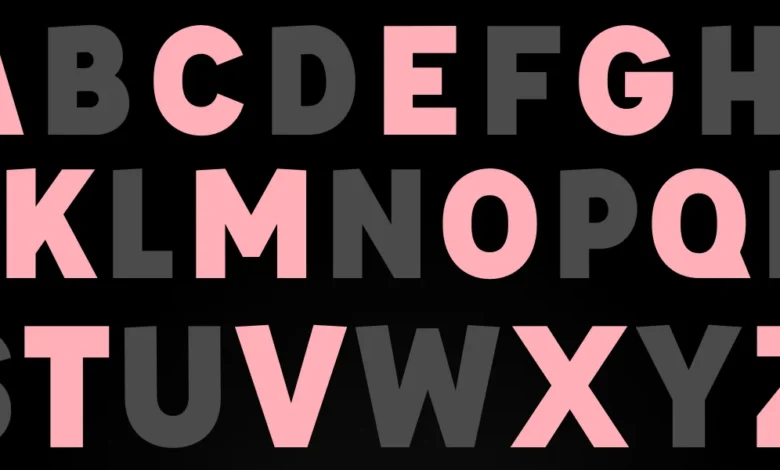
The evolution of Cascading Style Sheets (CSS) has been marked by a constant tension between the creative demands of web designers and the technical constraints of browser engines. For over two decades, one specific feature has remained at the top of developer wishlists: the ::nth-letter pseudo-element. This proposed selector would allow developers to target and style individual characters within a block of text based on their position, enabling advanced typographic effects such as staggered colors, skewing, or animated sequences without the need for manual Document Object Model (DOM) manipulation. Despite persistent advocacy from the design community and several experimental attempts at implementation, the feature remains absent from the official CSS specification as of 2024, forcing developers to rely on complex JavaScript workarounds and "shims."
A Chronology of Demand: Two Decades of Typographic Frustration
The desire for granular typographic control dates back to the early 2000s. In 2003, web standards advocate Anne van Kesteren first proposed the idea of expanding pseudo-elements beyond the existing ::first-letter and ::first-line selectors. At the time, the web was transitioning toward more sophisticated layouts, and designers sought to replicate print-media effects like drop caps and decorative initials across entire words or sentences.
The conversation gained significant momentum in 2011 when Chris Coyier, founder of CSS-Tricks, published a formal "Call for nth-everything." Coyier argued that if CSS could support :nth-child for elements, it should logically support ::nth-letter and ::nth-word for text nodes. This proposal suggested a syntax that would allow developers to write rules such as h1::nth-letter(even) to create alternating visual patterns.
In 2012, Adobe attempted to bridge this gap by introducing experimental support for ::nth-letter in the WebKit engine. However, the implementation faced significant hurdles regarding performance and internationalization, leading to its eventual abandonment. By 2017, the focus shifted toward "CSS Houdini," a collection of APIs intended to give developers low-level access to the browser’s CSS engine. Among these was the CSS Parser API, which many hoped would finally allow for the creation of custom styling languages and selectors. However, the CSS Parser API has remained in a draft state for years, leaving the community in a state of perpetual anticipation.
The Technical Difficulty of CSS Polyfilling
The concept of a "polyfill"—a piece of code that provides modern functionality on older browsers—is common in JavaScript but notoriously difficult in CSS. Philip Walton, a prominent engineer at Google, extensively documented these challenges in his research on the "dark side" of polyfilling CSS. Unlike JavaScript, where global functions can be "monkey-patched," CSS is parsed and applied by the browser in a way that is largely inaccessible to external scripts.
When a browser encounters a non-standard selector like ::nth-letter, the internal CSS parser identifies it as invalid and discards it immediately. This means that by the time a JavaScript-based polyfill attempts to read the stylesheets via the DOM’s styleSheets property, the custom selectors have already vanished. To circumvent this, developers must use a "shim" approach, which involves:
- Fetching Raw CSS: Using tools like
get-css-datato retrieve the raw text of all linked and internal stylesheets before the browser discards the "invalid" parts. - Regular Expression Transformation: Parsing the raw CSS text to find non-standard syntax and replacing it with valid, albeit more verbose, CSS.
- DOM Manipulation: Transforming the HTML structure to match the new CSS. For
::nth-letter, this typically requires splitting text strings into individual<span>or<div>elements, each containing a single character.
While effective for visual demonstrations, these methods are often criticized as "gross" or "hacky" because they fundamentally alter the markup for purely presentational purposes.
The Architectural Debate: Light DOM vs. Shadow DOM
In the pursuit of a cleaner implementation, some developers have turned to the Shadow DOM. The Shadow DOM allows for the encapsulation of structure and style, effectively hiding the "messy" character-splitting markup from the main document (the Light DOM). Under this model, a developer could use the ::part pseudo-element to style characters.
However, the Shadow DOM approach introduces its own set of limitations. The ::part selector is designed for encapsulation and does not natively support structural pseudo-classes like :nth-child from the outside. To make this work, a shim must pre-calculate the positions and assign specific part names, such as part="nth-child-1", to each character. Furthermore, elements moved into the Shadow DOM can lose their ability to inherit styles from the global scope, and they may break certain layout behaviors, such as those governed by CSS Grid or Flexbox, which rely on direct parent-child relationships.
Because of these trade-offs, many experts conclude that the Light DOM version—despite its impact on markup—remains the most robust option for cross-browser compatibility and styling flexibility.
Accessibility and Performance Implications
The primary argument against splitting text into individual character elements is the potential impact on accessibility. Screen readers, such as VoiceOver on macOS and iOS, have historically struggled with fragmented text. In some instances, a screen reader might treat each character as a separate word, leading to a disjointed and frustrating experience for visually impaired users.
Research into screen reader workarounds suggests that using the role="text" attribute or aria-label can mitigate some of these issues, but support is inconsistent across different software versions. The GSAP SplitText plugin, a popular tool for character-based animation, includes automated accessibility features to help maintain the integrity of the original text string. Nevertheless, the consensus among accessibility advocates remains that "perfect is the enemy of the good," and any DOM-splitting technique must be implemented with extreme caution.
From a performance perspective, splitting a long paragraph into hundreds of individual <span> elements can significantly increase the memory footprint of a page and slow down the rendering engine. This is one of the key reasons why browser vendors have been hesitant to implement ::nth-letter natively; the overhead of tracking and styling thousands of individual glyphs as separate "elements" could lead to severe "jank" during scrolling or window resizing.
The Internationalization Barrier
A significant factor delaying the standardization of ::nth-letter is the complexity of global languages. While the concept of a "letter" is straightforward in English, it becomes highly ambiguous in other writing systems.
- Ligatures and Clusters: In many scripts, multiple characters combine to form a single visual unit (a grapheme cluster). For example, in Devanagari or Arabic, a "letter" might be composed of several Unicode points.
- Punctuation: The existing
::first-letterpseudo-element often includes preceding punctuation (like a quotation mark) in its selection. Determining whether::nth-letter(3)should count a space or a comma as a "letter" creates a "lone crackpot" problem where any implementation choice will inevitably alienate a segment of the global user base. - Writing Direction: Right-to-left (RTL) and vertical writing modes add further layers of complexity to how "position" is calculated within a text node.
The World Wide Web Consortium (W3C) CSS Working Group must account for these edge cases before a feature can be moved to the "Candidate Recommendation" stage. The lack of a clear, universal definition for what constitutes an "nth letter" remains a primary technical blocker.
Broader Impact and the Future of Web Styling
The ongoing struggle to implement ::nth-letter serves as a microcosm for the broader challenges of web evolution. It highlights the gap between the rapid innovation seen in third-party libraries (like GSAP or Pretext.js) and the slow, deliberate pace of browser standardization.
The emergence of the "HTML-in-canvas" API and other experimental rendering methods suggests that the industry may eventually move toward a model where developers have even more control over the pixels on the screen. However, for the majority of the web, CSS remains the primary tool for design.
As of 2024, the "shim" remains the only viable path for those who refuse to wait. Experimental libraries available via platforms like npm have seen thousands of downloads, indicating a persistent demand. If these "hacks" become sufficiently prevalent, they may provide the browser gods—the engineers at Google, Apple, and Mozilla—with the empirical evidence needed to prioritize a native, performant implementation of ::nth-letter. Until then, the relationship between developers and CSS remains one of "tough love," characterized by a deep appreciation for the language’s power and a lingering frustration over its missing pieces.







{kind=link}