
The Evolving Landscape of Local Search

The utility of a truly effective location page extends far beyond mere digital presence. A meticulously crafted page can simultaneously serve multiple crucial functions: it can significantly improve organic search rankings, drive targeted local traffic, cultivate brand authority within specific geographic regions, provide essential information for direct customer engagement, and act as a high-converting landing page for paid advertising campaigns. This integrated performance is vital in an era where consumers increasingly rely on online searches—including voice-activated queries and AI-powered assistants—to find local businesses and services.
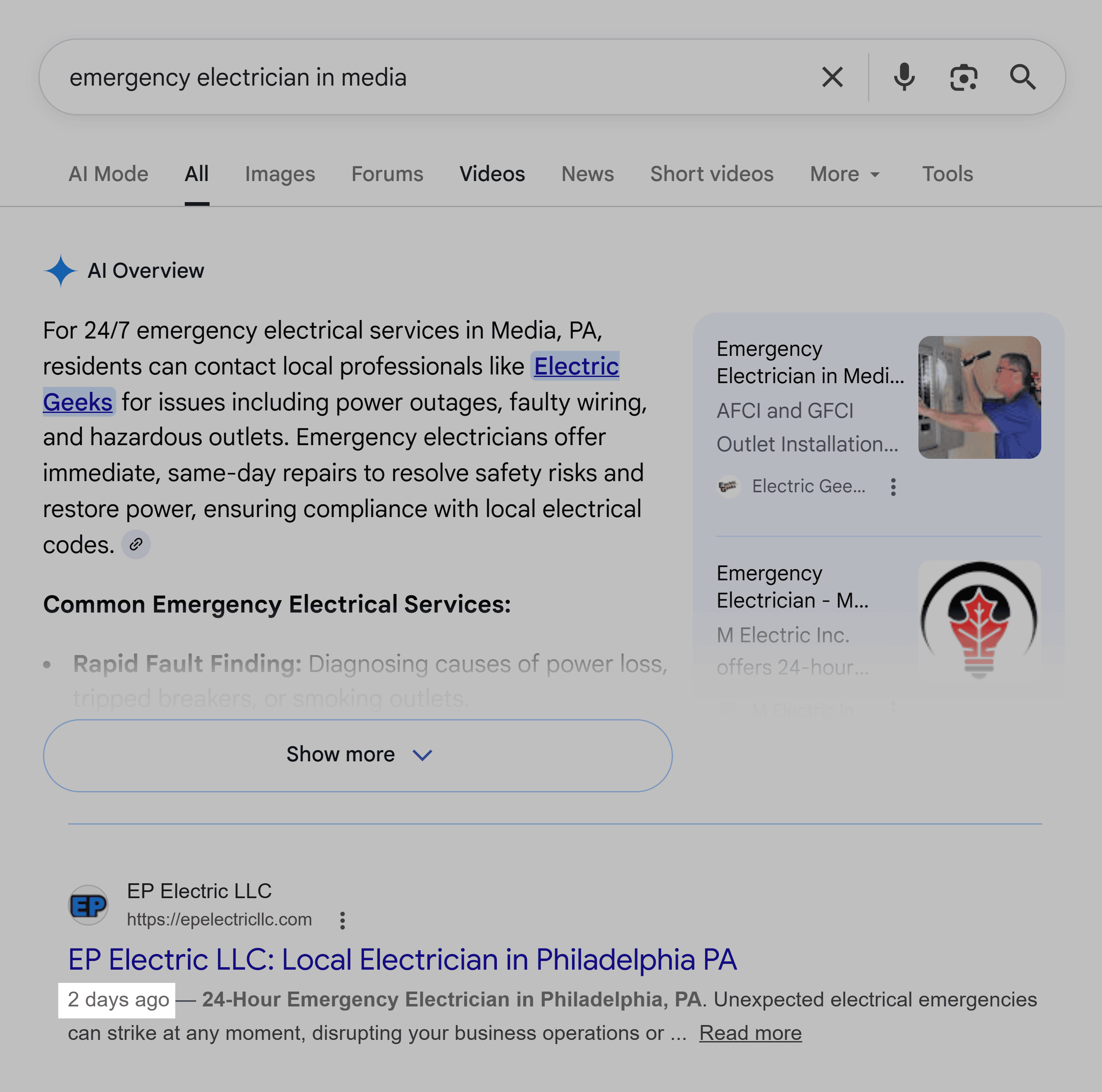
The evolution of local search engine optimization (SEO) has seen a dramatic shift from simple keyword matching to a sophisticated understanding of user intent and content quality. In the early days, merely stuffing geographical keywords onto a page might have sufficed. However, Google’s continuous algorithmic updates, including major shifts like Panda (focused on content quality), Hummingbird (understanding natural language queries), BERT (bidirectional encoders for transformer networks, enhancing context), and MUM (multitask unified model, for complex queries), have consistently prioritized valuable, unique, and user-centric content. The emergence of generative AI in search, exemplified by Google AI Mode, ChatGPT, and Perplexity, further intensifies the demand for structured, fact-rich, and locally relevant information that these systems can readily parse and cite. Businesses that fail to adapt to these changes find their location pages sitting idly online, technically live and indexed, but practically invisible and ineffective.
Drawing on extensive experience building high-ranking location pages for diverse businesses—from HVAC services and electricians to painters and funeral homes across numerous markets—it’s clear that rapid ranking isn’t a function of length or keyword density alone. Instead, success hinges on building pages specifically designed around how customers genuinely interact with a business in a given locality. This comprehensive guide outlines the precise methodology for developing location pages that resonate with business models ranging from multi-branch enterprises to service-area-focused operations, offering practical templates, advanced ranking tactics, and strategies for optimal visibility in AI-driven search results.

Distinguishing Between Location Page Types
A foundational step in crafting effective location pages is to correctly identify the type of page required for a specific business model. Misclassification can lead to user confusion, poor SEO performance, and missed opportunities with AI systems. Fundamentally, there are two primary categories:
-
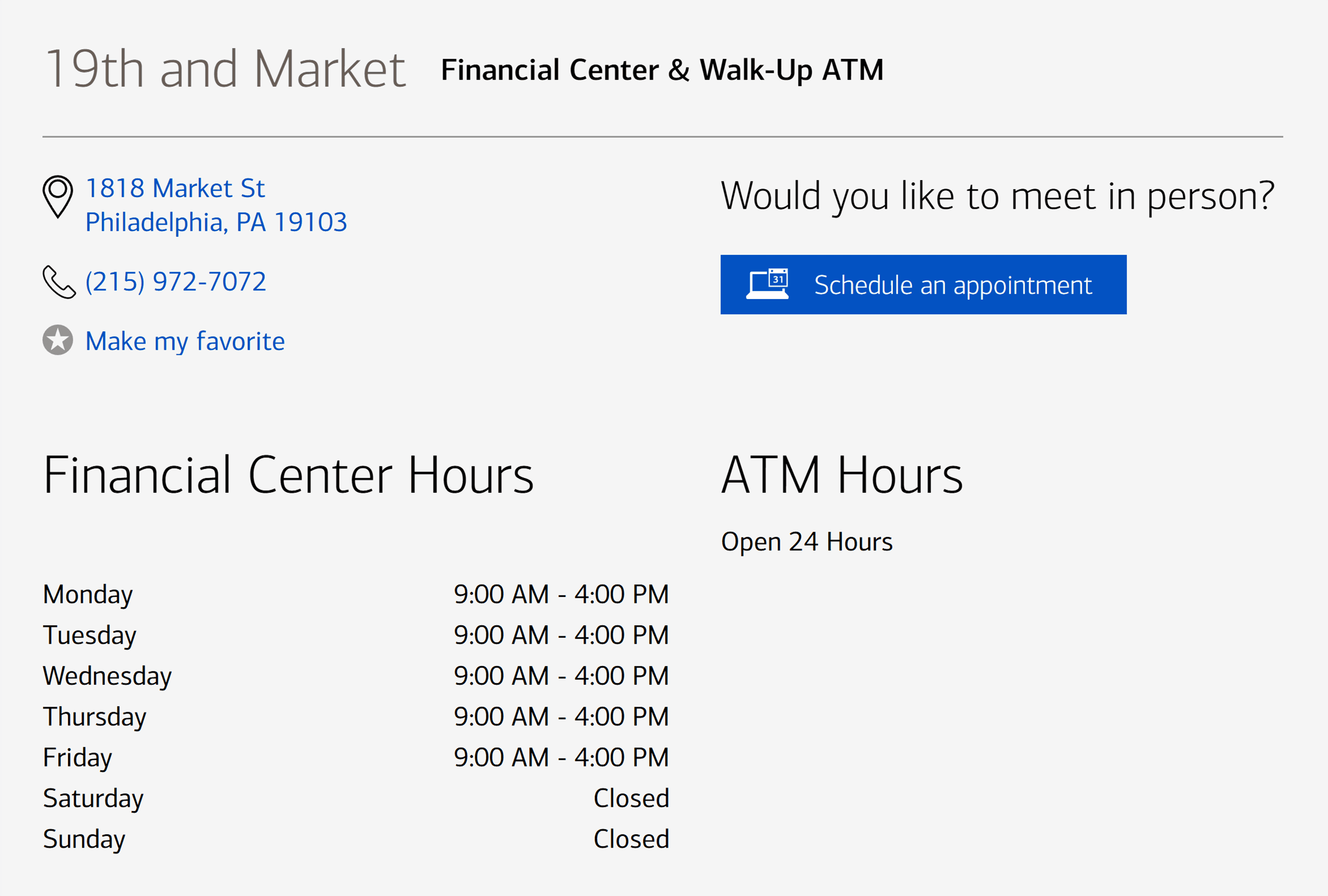
Physical Location Pages: These are designed for businesses with a tangible storefront, office, branch, restaurant, or clinic that customers physically visit. The content here must prioritize logistical details crucial for an in-person experience.
- Example: A Bank of America branch in Philadelphia needs a page detailing its full street address, precise operating hours, information on parking availability, ATM locations, and a description of in-branch services or amenities. This directly addresses the intent of a user looking to visit.
- Core Modules: Prominent address and contact information (NAP – Name, Address, Phone), interactive map (Google Maps embedding), clear operating hours, call-to-action (e.g., "Get Directions," "Schedule Appointment"), high-quality photos of the actual exterior and interior.
- Depth Modules: Hyperlocal content describing nearby landmarks, public transit options, and the neighborhood’s character. Extended FAQs covering common visitor queries ("Is there handicapped access?"), payment options, and specific services offered at that branch. Staff bios with headshots and specialties to build trust. Information on local community involvement (sponsorships, partnerships) to demonstrate authentic local presence.
-
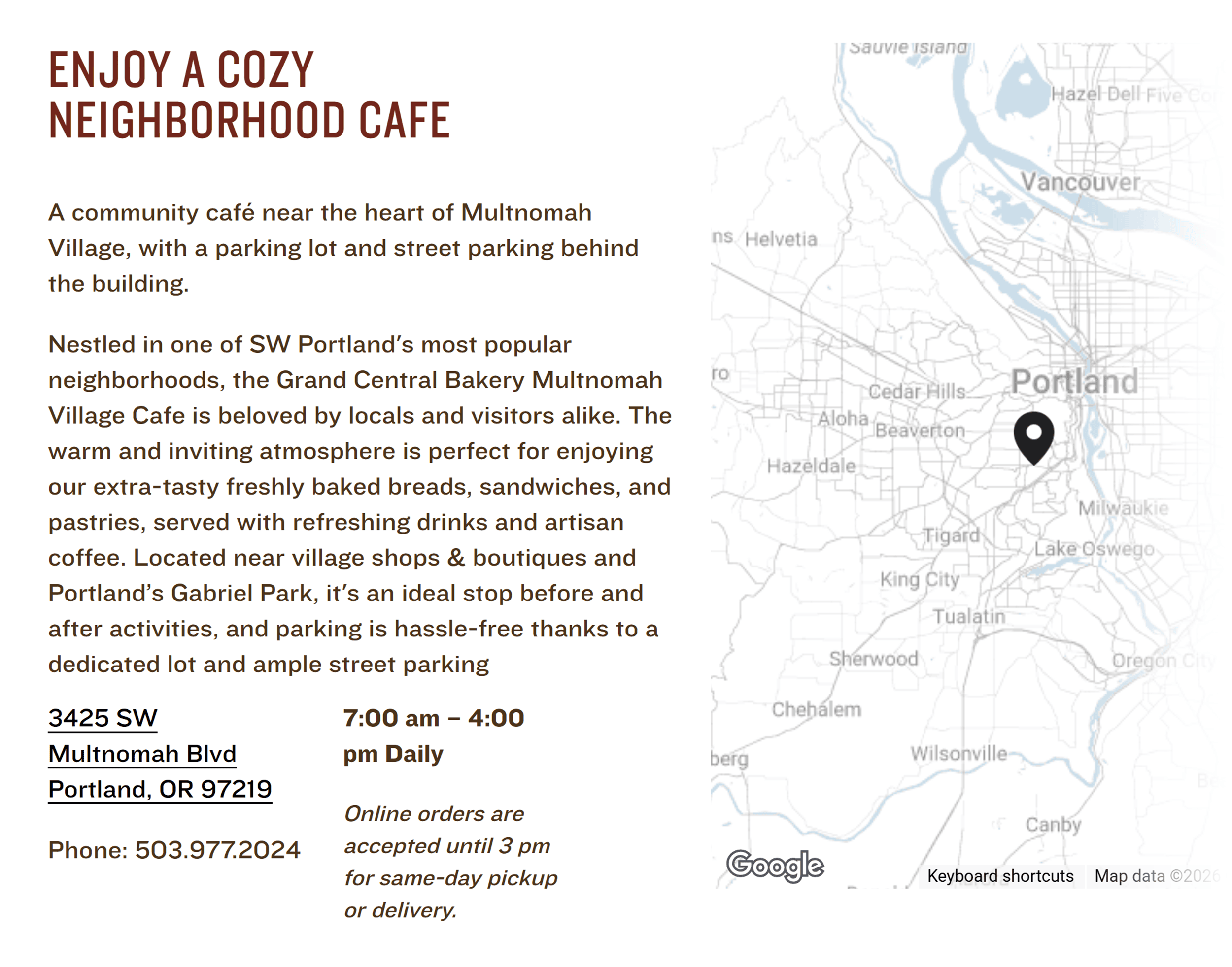
Service Area Pages: These pages are essential for businesses that serve a geographical region without maintaining a physical office within that specific town or city. This applies to mobile service providers (e.g., plumbers, roofers, pest control) and brick-and-mortar businesses that draw customers from surrounding communities. The focus here shifts to establishing credibility and local expertise.

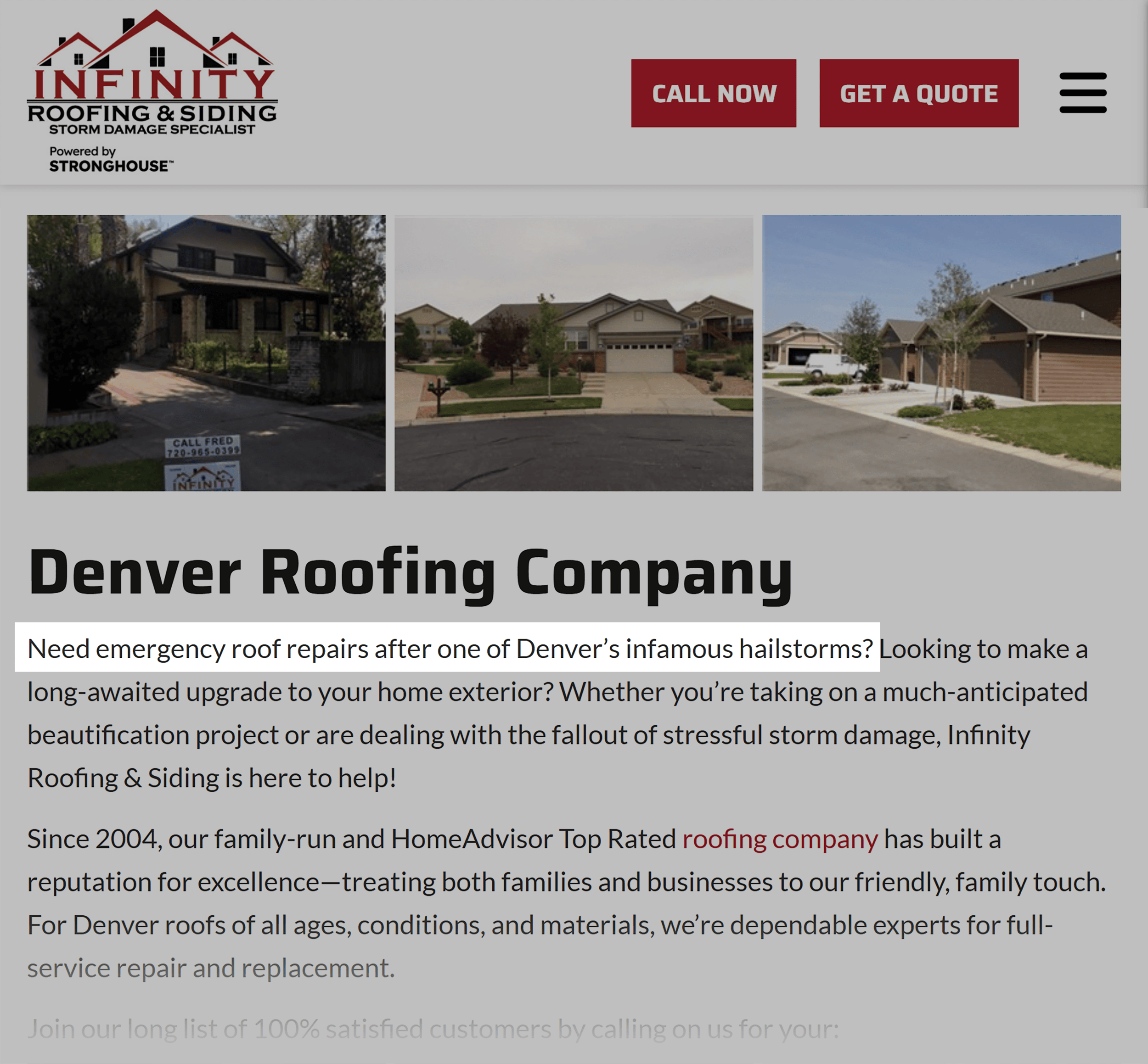
- Example: An HVAC company serving Southeastern Pennsylvania but without an office in Philadelphia needs a page that unequivocally states its service to Philadelphia residents, highlights its understanding of local climate challenges, and showcases customer testimonials from the area.
- Core Modules: Clear declaration of service to the specific area, prominent contact information (phone, lead form), list of services offered in that location, testimonials or reviews from local clients, and a clear call-to-action (e.g., "Request a Quote," "Book Service").
- Depth Modules: Hyperlocal content detailing unique regional challenges (e.g., "Denver’s infamous hailstorms" for a roofer, "hard water issues for Arizona pools"). Quantifiable data on previous work in the area (e.g., "completed 180+ pool installations in Scottsdale"). Extended FAQs addressing service logistics ("How quickly can you get here?") and technical questions tied to local conditions ("Do I need a permit for AC replacement in [city]?").
Many businesses require a hybrid approach. For instance, a funeral home with two physical offices might also serve numerous surrounding communities without dedicated branches. In such cases, physical location pages are created for the offices, while service area pages cover the neighboring towns. Crucially, these pages must be strategically interlinked: service area pages should link to the nearest physical location, and physical location pages should link out to the service areas they cover. This establishes a clear, navigable hierarchy for both users and search engines, enhancing both user experience and SEO performance.

Optimizing for Performance: Key Principles
Regardless of the page type, several core principles underpin the creation of high-performing location pages:
- Match Searcher Intent: A page must directly address what a user is looking for. For physical locations, this means logistics. For service areas, it’s about proving capability and trustworthiness. A mismatch inevitably leads to high bounce rates and poor engagement.
- Add Real Local Value: The most common failure is the use of generic, templated content with only city names swapped. Google’s algorithms are sophisticated enough to detect such "thin" or duplicate content, penalizing it. True local value comes from integrating neighborhood-specific details, discussing regional challenges, and showcasing expertise that only a local operator would possess. Examples include addressing historic preservation requirements for painting in a specific island community or discussing how local climate affects HVAC system sizing in a particular city.
- Right-Size Content Depth: The volume of content should align with the user’s decision-making process. High-consideration services (e.g., home remodeling, medical procedures, legal services) demand extensive information, often thousands of words, to address significant investments of time and money. These pages should cover diverse building types, specific challenges, and even pricing ranges. Conversely, low-consideration services (e.g., laundromats) can have leaner, more direct pages. Market competitiveness also dictates depth; highly competitive markets require more comprehensive content to differentiate.
- Consider Authority (Beyond Domain Score): While overall domain authority (AS) plays a role, well-optimized local pages can outrank high-authority competitors with thin content. The focus should be on building topical authority and direct relevance to local queries. This is achieved through intent-matching, unique local content, and targeted local backlinks from community organizations, news sites, and industry directories.
- Structure for AI and Search Engines: Technical SEO elements are non-negotiable. Implementing schema markup (LocalBusiness, FAQPage, Review at minimum) is crucial for search engines to understand the page’s content and context. Scannable sections with descriptive headings improve readability for both human users and AI systems, allowing them to quickly extract relevant information.
Multi-Channel Optimization for the Modern Web

Effective location pages must be optimized for diverse digital channels:

- Organic Rankings: Comprehensive content that answers user questions and addresses objections, naturally integrated keywords, and high-quality local backlinks are paramount. Real, authentic images of the business, team, or local projects significantly outperform generic stock photos.
- AI Citations: With the rise of AI in search, businesses must strategically position themselves to be cited by platforms like Google AI Mode, ChatGPT, and Perplexity.
- An experiment querying "best [service] in [city]" across these platforms revealed distinct citation patterns: Google AI Mode heavily cited Yelp listings (32%) and Reddit threads (30%), indicating a preference for user-generated content and community discussions. ChatGPT favored editorial "best of" lists (22%), highlighting the value of local media mentions. Perplexity, notably, cited business websites directly 73% of the time, emphasizing the importance of robust on-site content.
- Implications: Businesses need a multi-faceted approach. Strong Google My Business profiles and active engagement on review platforms are vital for Google AI. Public relations efforts targeting local magazines and online publications for "best of" features will benefit ChatGPT visibility. And critically, maintaining a highly informative, well-structured website is essential for Perplexity. Formatting content into comparison tables, pricing breakdowns, and clearly structured FAQ sections makes it easier for AI to parse and cite.
- Paid Landing Pages: Location pages serve as ideal landing pages for local Google Ads campaigns. Crucial for success is "message match": the exact promise made in the ad copy (e.g., "24/7 Emergency Plumber in Orange County") must be the first thing a user sees on the landing page, ideally in the headline. This improves Google’s Quality Score, leading to lower cost per click (CPC) and higher conversion rates. Specificity is key; an ad targeting "Landscaping Denver" should lead to a Denver-specific page, not a generic Colorado service area page.
Scaling for Enterprise Success

While the core principles apply universally, scaling location page strategies across multiple branches or extensive service areas introduces unique challenges and opportunities:

- Lock Down Brand Standards: Centralized templates are critical for maintaining brand consistency and preventing local teams from creating off-brand content. Defining editable elements (local details, testimonials) and locked elements (brand messaging, legal disclaimers) ensures quality. A dedicated style guide and approval workflows are essential.
- Avoid the Duplicate Content Trap: The primary risk at scale is creating hundreds of near-identical pages. Each page must have genuinely unique content that reflects the specific location’s nuances. Public Storage, for example, successfully creates unique content by tying each page to real places and explaining specific storage needs relevant to living there. Regular audits are necessary to identify and remediate thin or duplicate pages, as they can negatively impact the entire domain’s ranking.
- Choose Your Content Team Structure: A hybrid approach often yields the best results. A central team can manage templates, core messaging, and SEO best practices, while local teams contribute authentic hyperlocal details, testimonials, and insights. Clear ownership and regular refresh cadences prevent content from becoming stale.
- Connecting Physical Locations to Service Areas: For businesses with multiple physical offices serving numerous towns, a clear internal linking structure is crucial. Each service area page should link to its nearest physical location, and physical location pages should highlight the service areas they cover. This creates a logical hierarchy for both users and search engines, improving crawlability and authority distribution.
- Build Neighborhood Pages That Don’t Suck: Resist the urge to create a page for every single ZIP code. Prioritize creating fewer, high-quality neighborhood pages for competitive markets, areas with genuine search volume, and locations where real hyperlocal expertise can be demonstrated. Ten strong, unique neighborhood pages are far more effective than 100 weak, generic ones.
- Establish a Robust Production System: Utilize Content Management System (CMS) templates that enforce the desired structure and content requirements. Maintaining a comprehensive database or spreadsheet of all location pages, including URLs, last updated dates, and performance metrics, is vital for management and auditing. Automated alerts can flag pages that require updates. Programmatic SEO can be effective for large-scale operations if there is genuinely unique, dynamic data (e.g., real-time pricing, inventory, reviews) to populate each page, as seen with platforms like Expedia. However, if content is merely swapped city names, manual creation with deep local insights is preferable.
Conclusion: Start Small, Scale Smart
The journey to dominating local search and AI citations begins with a single, exceptionally well-built location page. Identify the highest-priority location or service area and invest in developing a page that meticulously adheres to the principles and templates outlined above. Instead of attempting a mass rollout of many pages, refine this initial page until it consistently ranks, converts, and garners AI citations. This proven model can then be replicated strategically across other locations. The competitive advantage lies in quality and depth; while many businesses settle for generic, ineffective pages, a commitment to detailed, user-centric, and locally valuable content will set a business apart in an increasingly AI-driven digital marketplace. This focused effort ensures that each location page functions as a powerful marketing asset, driving tangible business growth and establishing enduring local authority.






{kind=link}