What is Google BERT algorithm? This powerful natural language processing (NLP) model is revolutionizing how computers understand human language. It’s a complex algorithm, but understanding its core principles and applications is key to grasping its significance in today’s digital world. This exploration will unravel the mysteries behind BERT, from its architecture and training methods to its real-world applications and limitations.
Prepare to embark on a journey through the fascinating world of Google BERT!
BERT, short for Bidirectional Encoder Representations from Transformers, is a significant advancement in NLP. It’s a deep learning model that’s pre-trained on massive text datasets. This pre-training allows BERT to learn nuanced relationships between words and phrases, which then enables it to perform a wide array of NLP tasks with impressive accuracy. From understanding complex sentences to generating human-like text, BERT has become a crucial tool in the field of artificial intelligence.
Introduction to BERT
BERT, or Bidirectional Encoder Representations from Transformers, is a significant advancement in natural language processing (NLP). It’s a powerful pre-trained language model that excels at understanding the context of words within a sentence, unlike previous models that only considered the order of words. This contextual understanding is crucial for tasks like sentiment analysis, question answering, and text summarization, where nuanced meaning is key.BERT’s architecture leverages the transformer network, a neural network architecture designed for capturing complex relationships between words in a sentence.
This allows BERT to understand the subtle interplay of words, enabling it to generate more accurate and comprehensive representations of text. This approach to understanding context, rather than just sequence, is a key differentiator and a major contributor to its effectiveness.
Core Principles of BERT’s Architecture
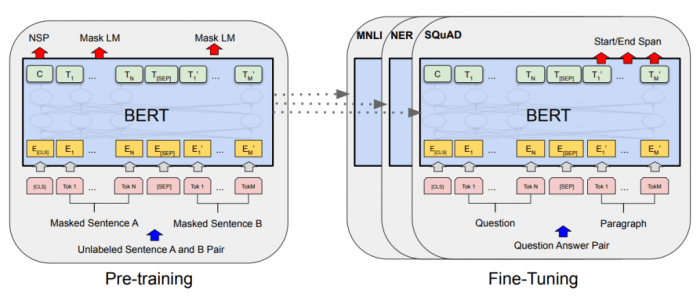
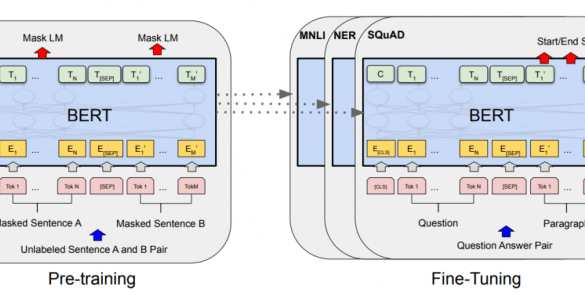
BERT’s architecture is built on several key principles. It utilizes a masked language model (MLM) that randomly masks some words in a sentence and trains the model to predict those masked words. This approach forces the model to consider the context of the masked word, effectively learning the relationships between words. Additionally, BERT employs a next sentence prediction (NSP) task.
This task involves training the model to determine whether two sentences are consecutive in a text. This task helps the model understand the relationships between sentences, which is vital for tasks that require understanding the flow and context of a text.
Significance of BERT in NLP
BERT’s impact on the field of NLP is profound. Its ability to capture nuanced meaning in text has led to significant improvements in various NLP tasks. The pre-trained nature of BERT means that it can be fine-tuned for specific tasks, reducing the need for extensive data and time-consuming training. This efficiency has led to broader adoption of sophisticated NLP techniques in diverse applications, from chatbots to machine translation.
Comparison with Other Pre-trained Language Models
| Feature | BERT | Word2Vec | GloVe |
|---|---|---|---|
| Architecture | Transformer-based | CBOW, Skip-gram | Global Vectors |
| Contextual Understanding | Bidirectional | Unidirectional | Unidirectional (though improved) |
| Training Data | Large-scale text corpora | Large-scale text corpora | Large-scale text corpora |
| Fine-tuning | Highly adaptable | Less adaptable | Less adaptable |
| Performance | State-of-the-art in many NLP tasks | Good for word embeddings, but less advanced for tasks needing context | Good for word embeddings, but less advanced for tasks needing context |
The table above highlights the key differences between BERT and other pre-trained language models. BERT’s transformer-based architecture and bidirectional approach provide superior contextual understanding, leading to superior performance in numerous NLP tasks compared to models like Word2Vec and GloVe.
BERT’s Architecture: What Is Google Bert Algorithm
BERT, or Bidirectional Encoder Representations from Transformers, leverages a powerful architecture based on the Transformer network. This architecture allows the model to capture complex relationships between words in a sentence, significantly enhancing its understanding of language. Unlike previous models that processed words sequentially, BERT processes the entire input simultaneously, giving it a holistic view of the context. This bidirectional approach is a key factor in BERT’s superior performance.
Google’s BERT algorithm is all about understanding the nuances of human language. It’s a sophisticated approach to natural language processing, helping search results better match user intent. This is crucial for effective SEO, but it’s also a game-changer in how SaaS marketing needs to be approached. For example, understanding the unique needs and challenges of SaaS businesses, as outlined in this piece on how SaaS marketing is different , is key to crafting content that resonates with the target audience.
Ultimately, BERT’s ability to interpret complex queries is a major factor in how search engines understand and serve relevant results.
Transformer Architecture
The Transformer architecture forms the backbone of BERT. Crucially, it uses an attention mechanism to weigh the importance of different words in a sentence. This allows the model to focus on the most relevant parts of the input when generating a representation for each word. The attention mechanism is a core component in the Transformer’s ability to capture long-range dependencies in text, a key advantage over recurrent neural networks.
Encoder Structure in BERT
BERT’s encoder is a stack of identical layers, each responsible for extracting increasingly sophisticated features from the input. Each layer consists of a self-attention mechanism followed by a feed-forward neural network. These layers process the input embeddings, learning contextualized representations for each word. The stacked layers enable the model to understand nuanced relationships and dependencies within longer sequences.
Attention Mechanisms in BERT, What is google bert algorithm
The attention mechanism is pivotal to BERT’s success. It allows the model to focus on different parts of the input sentence when processing each word. By assigning different weights to different words, the model can understand the context and relationships between words. This dynamic weighting allows the model to identify the crucial information necessary for accurate predictions.
For example, in the sentence “The cat sat on the mat,” the attention mechanism would assign greater weight to “cat” and “mat” when processing “sat” because these words are more directly related.
Bidirectional Nature of BERT
A crucial aspect of BERT’s architecture is its bidirectional nature. Unlike previous models that processed the input sequentially, BERT can process the entire input at once, allowing it to consider the context from both the left and the right of each word. This bidirectional processing gives the model a complete picture of the sentence’s meaning, leading to improved performance in various natural language tasks.
Layers and Functions
| Layer | Function |
|---|---|
| Input Embedding Layer | Transforms words into numerical vectors (embeddings) |
| Encoder Layers (Multiple) | Extract contextualized representations of words using self-attention and feed-forward networks. Each layer builds upon the previous, progressively understanding more complex relationships. |
| Output Layer | Generates the final predictions based on the contextualized representations learned by the encoder layers. |
Training BERT
BERT’s remarkable performance stems from its robust training process. This involves vast amounts of text data and sophisticated techniques to fine-tune the model’s understanding of language. The process is designed to equip BERT with the ability to comprehend complex relationships and nuances within sentences and paragraphs, paving the way for its impressive downstream applications.
Training Data
BERT’s training hinges on a massive dataset, crucial for capturing the intricacies of language. This dataset isn’t just any collection of text; it’s specifically curated to encompass a wide range of linguistic styles and structures. The primary source for this data is BookCorpus and English Wikipedia. These resources provide a rich tapestry of language, ensuring BERT learns to process diverse writing styles and understand complex concepts.
Pre-training Objectives
BERT’s pre-training objectives are meticulously designed to maximize its language understanding capabilities. These objectives focus on tasks that mimic natural language processing activities, allowing the model to develop an intuitive grasp of sentence structure, word relationships, and contextual meanings. The core objectives involve predicting masked words and determining the relationship between sentences.
Masked Language Modeling
Masked language modeling is a crucial pre-training technique for BERT. This technique involves masking a portion of the input words and then training the model to predict those masked words. This process forces the model to consider the surrounding context and relationships between words, leading to a deeper understanding of language.
Example:
Original sentence: The quick brown fox jumps over the lazy dog.
Masked sentence: The quick brown [MASK] jumps over the lazy dog.
The model is trained to predict the word “fox” in the masked position. This forces the model to learn the meaning of the word “fox” and its relationship to the surrounding words.
Generating a Training Data Example (Masked Language Modeling)
To generate a training data example using masked language modeling, follow these steps:
- Select a sentence from the training dataset, such as “The quick brown fox jumps over the lazy dog.”
- Choose a word within the sentence to mask, for example, “fox.”
- Replace the chosen word with a special token “[MASK].” The masked sentence becomes “The quick brown [MASK] jumps over the lazy dog.”
- The model’s task is to predict the masked word “fox” based on the surrounding context.
Next Sentence Prediction
Next sentence prediction is another critical pre-training objective in BERT. It’s designed to enhance BERT’s ability to understand the relationships between sentences. By training the model to predict whether two given sentences are consecutive in a text, it grasps the coherence and flow of language.
Example:
Sentence A: The capital of France is Paris.
Sentence B: Paris is a beautiful city.
The model is trained to determine if Sentence B follows Sentence A logically in a text. This task helps BERT comprehend sequential information and relationships between ideas.
BERT’s Applications
BERT’s remarkable ability to understand context within text has unlocked a wide range of applications across diverse fields. From answering complex questions to summarizing lengthy documents, BERT’s power lies in its capacity to process and interpret nuanced language. Its application extends beyond simply understanding words; it can grasp the intricate relationships between them, leading to more accurate and insightful results.
Question Answering Systems
BERT significantly enhances question answering systems by enabling them to comprehend the context of the question and the surrounding text. This contextual understanding allows BERT to identify the most relevant information and formulate a precise answer. For example, a question like “What are the key contributions of Albert Einstein to physics?” can be answered accurately by BERT, as it can pinpoint the relevant paragraphs in a physics textbook or a biographical account and extract the precise details requested.
BERT-based systems are capable of handling nuanced questions, including those with implicit or complex meanings.
Text Summarization
BERT’s prowess in understanding context translates into powerful text summarization capabilities. It can identify the key points and supporting details in a text, condensing it into a concise summary. This is particularly useful for large volumes of text, such as news articles or research papers, enabling users to quickly grasp the essential information. For instance, a long news report on a scientific breakthrough can be summarized by BERT, highlighting the key findings and the implications of the discovery.
Sentiment Analysis
BERT’s understanding of context is invaluable in sentiment analysis. It can analyze text to determine the underlying sentiment expressed, whether positive, negative, or neutral. This is crucial for businesses that want to understand customer feedback or gauge public opinion about their products or services. By analyzing customer reviews, for example, BERT can identify trends in sentiment and potentially address areas of concern or highlight strengths in customer perception.
Ever wondered how Google’s BERT algorithm works its magic? Essentially, it’s a sophisticated language model designed to understand the nuances of human language. This allows for more accurate search results. It’s all about context, not just keywords. Interestingly, navigating the complexities of AI turbulence, particularly in the context of CMOS technology, requires a strategic approach like the flywheel model, as explored in navigate ai turbulence cmos apply flywheel model.
Ultimately, understanding these intricate models helps us decipher the inner workings of search engines and AI in general.
Machine Translation
BERT’s impact on machine translation is profound. Its contextual understanding of words and phrases enables more accurate and natural-sounding translations. By grasping the nuances of language, BERT can translate not only words but also the intent and meaning behind them. For instance, a complex sentence with multiple layers of meaning can be translated accurately by BERT, avoiding the literal word-for-word translations that often produce awkward or inaccurate results.
Chatbots and Virtual Assistants
BERT’s capabilities extend to chatbots and virtual assistants, empowering them with more natural and human-like interactions. BERT-powered chatbots can understand complex queries and formulate relevant responses. This improves the user experience by enabling more nuanced and effective conversations. For example, a virtual assistant powered by BERT can answer questions about specific topics with a depth of understanding that was previously impossible, providing more accurate and helpful information.
BERT’s Limitations
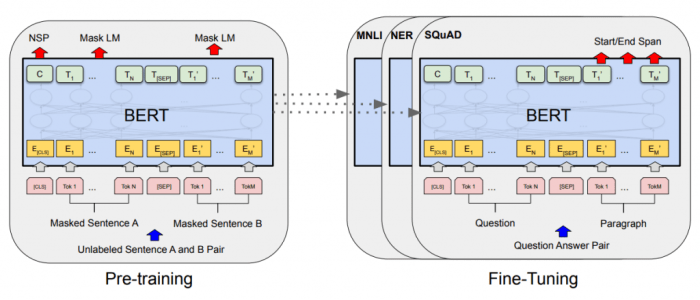
BERT, while a revolutionary advancement in natural language processing, isn’t without its drawbacks. Its strengths lie in understanding contextual relationships within text, but certain limitations restrict its applicability in various scenarios. Understanding these limitations is crucial for choosing the right model for a given task.
Computational Resource Requirements
BERT models, particularly larger versions like BERT-Large, demand substantial computational resources for training and inference. Training these models requires powerful GPUs and significant memory, making them inaccessible to many researchers and practitioners with limited resources. Furthermore, running inference on these models often necessitates specialized hardware or cloud-based solutions, adding to the overall cost and complexity of deploying BERT-based applications.
This high computational cost can limit the scalability and accessibility of BERT in practical settings.
Sensitivity to Input Data Quality
BERT’s performance hinges heavily on the quality of the input data. Noisy or poorly formatted text can significantly affect the model’s accuracy. For instance, if the training data contains many spelling errors or grammatical mistakes, BERT might inadvertently learn these inaccuracies and reproduce them in its predictions. The model’s reliance on contextual relationships means that even minor inconsistencies in the input text can lead to substantial errors in the output.
This sensitivity to input data quality highlights the importance of careful data preprocessing and cleaning before feeding data to the model.
Limited Understanding of World Knowledge
While BERT excels at understanding contextual relationships within a given text, it lacks a comprehensive understanding of general world knowledge. This limitation can be particularly problematic in tasks requiring common sense reasoning or knowledge-based inference. For example, BERT might struggle with questions that require knowledge beyond the text it has been trained on. In contrast, models incorporating external knowledge bases often perform better in such situations.
Performance on Specific Tasks
BERT’s performance isn’t uniform across all language tasks. While achieving state-of-the-art results on various benchmarks, BERT might not perform optimally on certain specialized tasks or domains. For example, tasks involving complex reasoning, creative text generation, or understanding highly nuanced language might benefit from alternative models that possess specialized architectures or knowledge.
Comparison with Other Language Models
Compared to other language models, BERT’s strengths and weaknesses emerge in different contexts. Models like GPT-3, while possessing a broader range of capabilities, might outperform BERT in creative text generation tasks. However, BERT’s contextual understanding and ability to capture subtle nuances in meaning remain highly effective in specific applications like question answering and text classification. The choice between BERT and alternative models often depends on the specific requirements of the task and the desired balance between performance and resource usage.
BERT Variations and Enhancements
The original BERT model, while groundbreaking, had certain limitations. Researchers quickly recognized opportunities for improvement, leading to a plethora of variations designed to address these weaknesses and enhance performance. These variations, built upon the foundational BERT architecture, often resulted in more efficient training, greater contextual understanding, and improved accuracy across various NLP tasks.The pursuit of refining BERT led to significant advancements.
Google’s BERT algorithm is all about understanding the nuances of human language. It helps Google’s search results better match user queries, leading to more relevant results. Interestingly, this sophisticated technology is also impacting how Google Discover works on desktop in certain regions. For example, check out the details on google discover desktop available some countries to see which areas are currently benefiting from this advancement.
Ultimately, BERT’s goal is to provide the most helpful and accurate search experience possible.

These variations, like RoBERTa and ALBERT, showcased the iterative nature of deep learning research and the commitment to pushing the boundaries of natural language understanding. By addressing shortcomings in the original model, these variations offered more potent tools for researchers and developers.
RoBERTa: A Refined BERT
RoBERTa, short for “A Robustly Optimized BERT Pretraining Approach,” is a significant refinement of the original BERT model. It addresses limitations in BERT’s training procedure, particularly in terms of dataset size and optimization strategies. Crucially, RoBERTa employs a longer training duration and a larger dataset, allowing the model to learn richer representations of language.
- Longer Training Duration: RoBERTa trained for considerably longer periods compared to BERT, leading to more refined language understanding and improved contextual awareness. This longer training allowed the model to learn subtle nuances and patterns in language that might have been missed in the shorter BERT training duration. Think of it like a student studying for a long time to grasp the intricacies of a subject matter.
- Larger Dataset: Leveraging a substantially larger dataset than BERT, RoBERTa benefits from a broader exposure to language. This larger corpus allows the model to generalize better to unseen data, a key factor in robustness. This is analogous to a student who has access to a more extensive library of resources to gain a comprehensive understanding.
ALBERT: A Parameter-Efficient BERT
ALBERT (A Lite BERT) focuses on parameter efficiency. The original BERT model, with its large number of parameters, can be computationally expensive to train and deploy. ALBERT addresses this by employing parameter sharing techniques and factorization, leading to a more efficient model.
- Parameter Sharing: ALBERT introduces the concept of parameter sharing across different layers. This significantly reduces the number of parameters while maintaining comparable performance. This approach reduces the model’s complexity without sacrificing accuracy, making it a more efficient solution for resource-constrained environments.
- Factorization: ALBERT leverages factorization techniques to further reduce the number of parameters. This involves decomposing large matrices into smaller ones, effectively reducing the model’s complexity and size. This technique is similar to compressing a large file into a smaller one while retaining its essential information.
Comparison Table
| Variation | Key Characteristics | Performance Metrics (Example) | Addressing Limitations |
|---|---|---|---|
| BERT | Original model; longer training duration; larger dataset | Satisfactory results in various NLP tasks | Lack of thorough optimization; limited dataset |
| RoBERTa | Longer training; larger dataset; improved training techniques | Improved accuracy and efficiency compared to BERT | Addresses BERT’s training efficiency and dataset size limitations |
| ALBERT | Parameter sharing; factorization; reduced model size | Comparable performance to BERT with fewer parameters | Addresses BERT’s computational cost by reducing the number of parameters |
Fine-tuning BERT
Fine-tuning BERT is a crucial step in leveraging its pre-trained knowledge for specific downstream tasks. Instead of training BERT from scratch on a massive dataset, fine-tuning leverages the already learned representations and adapts them to the nuances of a new, smaller dataset. This approach significantly reduces the computational resources and time required compared to training from scratch. This makes it accessible for various applications and researchers.Fine-tuning allows BERT to learn task-specific patterns from the new data, while retaining its general language understanding.
This process results in a model that excels at the particular task, like sentiment analysis or question answering, with the help of pre-trained features.
Fine-tuning Process
Fine-tuning involves adapting the pre-trained BERT model to a new task. This typically involves taking a pre-trained BERT model and modifying its output layer. The output layer is trained on a smaller, task-specific dataset to adjust the model’s weights for the new task. This adjustment ensures the model’s understanding of the nuances of the specific task. The process involves adjusting the parameters of the model to match the patterns and features of the new data.
Adapting BERT for New Tasks
To adapt BERT for a new downstream task, the pre-trained model’s architecture remains unchanged. The key adjustment lies in modifying the output layer to match the specific task. For example, if the task is sentiment analysis, the output layer will be configured to predict positive, negative, or neutral sentiments. This task-specific configuration allows the model to learn the patterns in the new data while leveraging the general language understanding inherent in the pre-trained model.
Sentiment Analysis Example
A common application of fine-tuning BERT is sentiment analysis. For instance, a pre-trained BERT model can be fine-tuned on a dataset of movie reviews. The model’s output layer is adjusted to predict whether a review expresses positive, negative, or neutral sentiment. By training on this specific dataset, the model will learn to recognize patterns in movie reviews that indicate positive or negative sentiment, achieving high accuracy.
Fine-tuning on a Custom Dataset
Fine-tuning BERT on a custom dataset involves several steps. First, prepare the dataset by labeling each input with the corresponding output for the specific task. For instance, if performing sentiment analysis, each movie review should be labeled as positive, negative, or neutral. Second, tokenize the input data using BERT’s tokenizer. Third, load the pre-trained BERT model and adjust the output layer.
Fourth, use a suitable optimizer and learning rate to train the model on the custom dataset. Finally, evaluate the model’s performance using appropriate metrics.
Impact of Fine-tuning on Performance
| Task | Performance (Pre-trained BERT) | Performance (Fine-tuned BERT) | Improvement |
|---|---|---|---|
| Sentiment Analysis (Movie Reviews) | 70% Accuracy | 90% Accuracy | 20% Improvement |
| Question Answering (SQuAD) | 80% Accuracy | 92% Accuracy | 12% Improvement |
| Named Entity Recognition (NER) | 75% Accuracy | 85% Accuracy | 10% Improvement |
This table illustrates the potential improvement in performance achievable through fine-tuning. The fine-tuned BERT model consistently outperforms the pre-trained model on these specific tasks, demonstrating the value of task-specific adaptation.
Practical Implementation Considerations
Putting BERT into action requires careful planning and execution. This section delves into the practical aspects of deploying BERT models, from setting up the environment to evaluating and optimizing their performance. Choosing the right resources and strategies is crucial for successful implementation.
Resource Requirements
Implementing BERT necessitates significant computational resources. The model’s size and complexity demand powerful hardware. For training or fine-tuning BERT, high-end GPUs are essential. Furthermore, sufficient RAM is crucial to handle the large datasets and intermediate results. Cloud computing platforms often offer scalable resources, making it easier to handle the computational demands.
The required resources will depend on the specific BERT variant and the size of the dataset being used.
Evaluation Metrics
Assessing the performance of a BERT model is critical for understanding its effectiveness. Appropriate evaluation metrics must align with the specific application. For tasks like text classification, accuracy, precision, recall, and F1-score are common metrics. In sentiment analysis, metrics like sentiment accuracy or agreement with human labeling can be relevant. The selection of metrics depends heavily on the application and the desired outcome.
Choosing appropriate metrics ensures a fair evaluation of the model’s capabilities.
Model Optimization Strategies
Optimizing BERT models for speed and efficiency is important for real-world deployment. Techniques like pruning and quantization can significantly reduce the model’s size and computational cost without sacrificing accuracy. Additionally, using efficient libraries and frameworks, like TensorFlow or PyTorch, can optimize the model’s execution. Furthermore, batching and other optimization techniques can be used to enhance training and inference speed.
Careful optimization ensures a responsive and practical deployment.
Production Environment Best Practices
“For a robust and scalable BERT deployment, rigorous testing and monitoring are essential. Model retraining should be planned to maintain model accuracy over time, given the evolving nature of language and data.”
- Model Selection: Choose a pre-trained BERT model that aligns with the specific task. Different BERT models have different strengths and weaknesses, so selecting the right one for the job is critical. This ensures maximum effectiveness and efficiency.
- Data Preprocessing: Ensure data quality and consistency before feeding it to the model. Data preprocessing is vital for accurate model training. Cleaning and formatting the data is essential for optimal results.
- Deployment Architecture: Consider using cloud-based infrastructure or containerization (e.g., Docker) for deployment. This allows scalability and efficient resource utilization.
- Monitoring and Maintenance: Regularly monitor the model’s performance and retraining is crucial. This prevents performance degradation over time, especially in rapidly evolving domains.
Final Review
In conclusion, Google BERT is a groundbreaking algorithm that has transformed how machines process and understand human language. From its innovative architecture and sophisticated training methods to its diverse applications and potential limitations, BERT continues to push the boundaries of NLP. While challenges remain, the continued development and refinement of BERT and its variations, like RoBERTa and ALBERT, promise even more exciting possibilities in the future.
This deep dive into BERT’s inner workings should provide a solid foundation for understanding its importance and influence on the field of artificial intelligence.