Google Search Console crawl stats offer a fascinating window into how Googlebot, the search engine’s crawler, interacts with your website. Understanding these stats is crucial for website performance, as they reveal potential issues, allowing you to optimize your site for better search visibility. This deep dive into Google Search Console crawl stats explores the vital metrics, interpreting the data, diagnosing problems, and optimizing for enhanced crawling efficiency.
We’ll unpack how to use this data for website improvement and even for strategic content planning.
This in-depth exploration begins with a fundamental understanding of crawl stats, delving into the metrics they provide. We’ll break down common errors and their potential causes, helping you identify problems quickly. Then, we’ll move onto effective interpretation, showing you how to identify patterns and trends in crawl data. We’ll cover methods to compare crawl data across different timeframes, and explore the relationship between crawl rate and website performance.
Diagnosing crawl issues becomes straightforward with the practical steps Artikeld. We’ll look at common crawl errors, their impact on search visibility, and how to pinpoint the root causes.
Understanding Crawl Stats
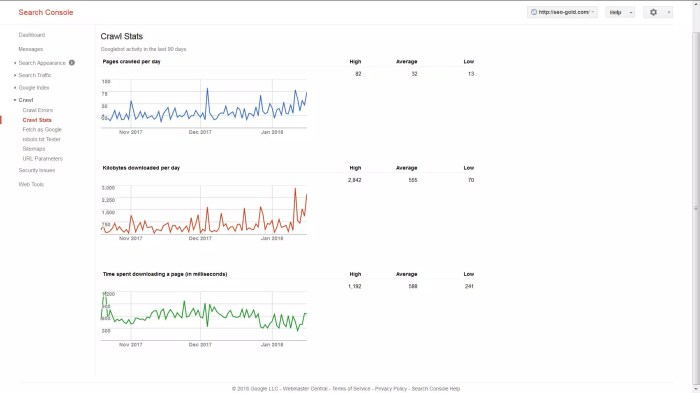
Google Search Console crawl stats provide valuable insights into how Googlebot, the search engine’s web crawler, interacts with your website. This data allows you to identify potential issues impacting your site’s visibility and discover opportunities for improvement. Understanding these metrics is crucial for optimizing website performance and ensuring your content is accessible to search engines.Crawl stats reveal how effectively Googlebot is navigating your site.
Comprehensive reports detail the pages crawled, the speed of crawling, and any encountered problems. This information is vital to maintaining a healthy website structure that facilitates efficient indexing and ranking.
Crawl Stats Metrics
Crawl stats reports encompass various metrics, each contributing to a holistic understanding of your site’s health. Key metrics include the number of pages crawled, crawl errors encountered, and the time taken to crawl your website. Analyzing these figures provides crucial data to identify potential problems and make necessary adjustments.
Page Crawled
The number of pages crawled reflects the extent of Googlebot’s exploration of your website. A significant drop in the number of pages crawled can indicate a problem with your site’s structure, such as broken links, or incorrect use of robots.txt. Conversely, a steady increase suggests your site is being properly indexed and is well-structured.
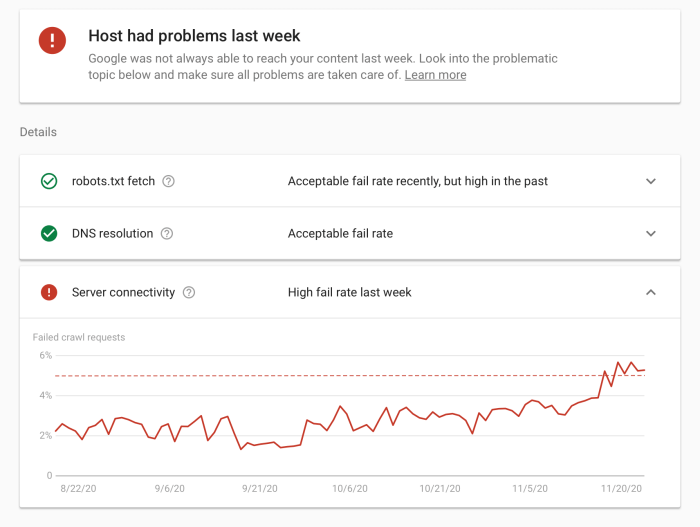
Crawl Errors
Crawl errors signify issues Googlebot encounters while attempting to access your site. These errors can range from simple problems like a 404 error (page not found) to more complex issues involving server problems. Regular monitoring of crawl errors is essential to address and resolve them promptly to prevent impacting your website’s visibility.
Crawl Depth
Crawl depth measures how many levels of pages Googlebot successfully navigates within your website. A low crawl depth may indicate issues with internal linking, making it challenging for Googlebot to discover all important content.
Crawl Rate
Crawl rate refers to the frequency at which Googlebot visits your website. High crawl rates can overwhelm your server, leading to performance issues, while low rates can hinder the indexing of new content. Optimizing the crawl rate is essential for maintaining website performance and ensuring timely indexing of new content.
Crawl Time
Crawl time measures the total time taken by Googlebot to crawl your website. A sudden increase in crawl time could indicate issues with server response times or slow loading pages.
Common Crawl Errors and Their Causes
| Error Type | Possible Cause | Impact | Resolution |
|---|---|---|---|
| 404 errors | Broken links, removed pages | Poor user experience, lower rankings | Fix broken links, implement redirects |
| robots.txt issues | Incorrect or missing robots.txt | Prevent search engine from crawling certain pages | Verify robots.txt is correct |
| Server Errors (5xx) | Temporary server issues, server overload | Prevent search engine from accessing pages | Resolve server issues, improve server resources |
| DNS Errors | Problems with your domain’s DNS settings | Prevent search engine from finding your website | Verify DNS settings, check for propagation delays |
Interpreting Crawl Data: Google Search Console Crawl Stats
Understanding your Google Search Console crawl data is crucial for optimizing your website’s performance. This data provides valuable insights into how Googlebot interacts with your site, revealing potential issues and opportunities for improvement. Effectively interpreting this data allows you to proactively address problems and ensure your site is well-indexed and easily discoverable.Interpreting crawl data isn’t just about recognizing numbers; it’s about understanding the story behind the metrics.
By meticulously analyzing patterns, trends, and variations, you can identify areas where your site excels and where it might need attention. This proactive approach empowers you to maintain a healthy website and improve your search engine rankings.
Steps to Effectively Interpret Crawl Data
Analyzing crawl data requires a systematic approach. Start by meticulously reviewing the data, focusing on both the overall trends and specific details. Look for anomalies, patterns, and any inconsistencies that may indicate potential problems or opportunities.
My Google Search Console crawl stats are looking a little sluggish lately. I’m trying to figure out if I need to invest more in content marketing or if a paid advertising boost might be a faster route to increased visibility. Ultimately, it boils down to comparing the ROI of different strategies, like in this insightful article about comparing the ROI of content marketing and paid advertising.
Hopefully, a deeper dive into these metrics will help me optimize my content strategy and see a positive impact on my crawl stats again.
- Examine the crawl frequency: How often is Googlebot crawling your site? A high crawl frequency typically indicates a healthy site, well-structured for indexing. Conversely, a low crawl frequency might signal issues with site architecture, content, or technical problems that need immediate attention.
- Identify crawl errors: Pay close attention to crawl errors reported in the Search Console. These errors provide specific details about the problems Googlebot encountered while trying to access and index your pages. Understanding the types of errors (e.g., robots.txt issues, server errors) helps pinpoint the cause and implement necessary fixes.
- Analyze crawl depth: How many pages of your site is Googlebot successfully crawling? A deep crawl indicates a well-structured site with logical navigation. Limited crawl depth could suggest issues with sitemaps, broken links, or complex site architectures, impacting Google’s ability to fully index your content.
- Review the requested URLs: Carefully examine the URLs that Googlebot requests. This helps you understand which pages are being prioritized for crawling. This can be used to identify pages that are missing or not being indexed correctly, providing a clearer understanding of the content visibility.
Identifying Patterns in Crawl Data
Looking for recurring patterns in crawl data is essential for understanding how Googlebot interacts with your site. Consistent issues or variations can pinpoint recurring problems or opportunities.
- Look for recurring crawl errors: If certain types of errors consistently appear, investigate the underlying causes. This might be a technical problem, such as a broken link or server issue, which should be prioritized for fixing. Persistent errors might indicate a broader systemic problem requiring attention.
- Analyze the frequency of crawl requests: A consistent drop or spike in crawl frequency could indicate seasonal changes or a technical issue. Identify the reasons behind the changes to make informed decisions and proactively address any underlying problems.
- Review the types of URLs crawled: The URLs that Googlebot prioritizes often reflect the structure and popularity of your content. Reviewing the types of URLs that are crawled, along with their frequency, helps in understanding the effectiveness of your site’s architecture.
Identifying Trends in Crawl Behavior Over Time
Tracking changes in crawl behavior over time provides valuable insights into the health of your site. Identifying trends helps you predict future crawl patterns and adapt your strategies accordingly.
- Observe changes in crawl frequency: If the crawl frequency is increasing or decreasing over time, investigate the underlying reasons. Changes could be due to content updates, technical improvements, or even external factors impacting Googlebot’s crawling behavior.
- Analyze the progression of crawl errors: Tracking the evolution of crawl errors reveals potential problems or opportunities. If certain errors are decreasing over time, this suggests that fixes implemented are effective. Conversely, an increase in specific errors may highlight an emerging technical problem.
- Review the changes in the URLs being crawled: Analyzing how the crawled URLs change over time gives insights into how Googlebot’s perception of your site evolves. A shift in the focus of crawled URLs might indicate the need to optimize or update your sitemap or content structure.
Comparing Crawl Data Across Different Periods
Comparing crawl data across different time periods allows for a deeper understanding of how your site is performing. This analysis reveals trends and allows you to evaluate the effectiveness of implemented changes.
- Establish baselines: Before making changes to your website, establish a baseline by collecting crawl data over a period of time. This baseline serves as a benchmark for evaluating the impact of future changes.
- Analyze changes after updates: After implementing changes (e.g., site restructuring, content updates), compare the new crawl data with the baseline data. This comparison reveals how the implemented changes affect the crawling behavior of Googlebot.
- Track seasonal patterns: Seasonal fluctuations in crawl data are common. Understanding these patterns can help you identify anomalies and avoid drawing incorrect conclusions about the performance of your site.
Crawl Rate and Website Performance
The crawl rate directly correlates with website performance. A high crawl rate usually indicates a healthy site, whereas a low crawl rate may suggest potential issues.
Google Search Console crawl stats are super helpful for seeing how often Googlebot visits your site. But understanding where those backlinks are landing on your site—and how effective they are—is crucial for optimizing those crawl stats. For example, checking the backlinks effectiveness page location helps you pinpoint if backlinks are targeting the most important pages for conversions.
Ultimately, stronger insights into where backlinks are pointing lead to more efficient Googlebot crawls and higher search rankings.
| Crawl Rate | Website Performance | Possible Implications |
|---|---|---|
| High crawl rate | Likely good performance | Likely healthy site, good indexing |
| Low crawl rate | Potential for performance issues | Possible problems with site architecture or content |
Diagnosing Crawl Issues
Troubleshooting crawl errors is crucial for maintaining a healthy website and maximizing search visibility. Understanding crawl errors and their potential impact is the first step in identifying and fixing problems. This involves analyzing crawl data, identifying patterns, and prioritizing issues based on their severity. Addressing these errors can lead to significant improvements in search engine rankings and user experience.Crawl errors, if left unaddressed, can negatively affect your website’s visibility in search results.
These errors can stem from technical issues on your site, problems with external links, or even changes in Google’s crawling algorithms. Identifying and resolving these errors is essential to ensure your website is easily discoverable by search engines.
Identifying Potential Crawl Issues
Analyzing crawl data is the key to pinpointing problems. Patterns in crawl errors, such as repeated 404 errors or high numbers of blocked URLs, provide valuable insights. Thorough examination of the data allows for a systematic approach to identify potential issues. This process helps prioritize issues based on their potential impact on search visibility. For example, a large number of blocked resources might indicate a misconfiguration of the robots.txt file.
Prioritizing Crawl Issues
Prioritizing crawl issues is essential for efficient problem-solving. Issues with higher frequency and those affecting more critical parts of the website should be addressed first. For example, frequent 404 errors pointing to important pages should be tackled before addressing less frequent errors on less-visited pages. This strategic approach ensures that the most impactful issues are tackled first, leading to faster improvements.
Investigating Root Causes of Crawl Errors
Thorough investigation of the root causes of crawl errors is critical. This involves examining server logs, checking for broken links, and ensuring the correct configuration of robots.txt. For instance, reviewing server logs can pinpoint the exact nature of a 500 error, helping in identifying the underlying cause. This process requires a methodical approach and careful analysis of various data sources.
Common Crawl Errors and Their Impact
Understanding the common crawl errors and their potential impact on search visibility is crucial for effective troubleshooting. These errors, such as 404 errors or server errors, can negatively affect search rankings by hindering the crawling process. Common errors, like blocked resources, can significantly reduce the amount of indexed content, thereby limiting your site’s visibility.
Table of Common Crawl Errors and Resolutions
| Error Type | Description | Possible Resolutions |
|---|---|---|
| Blocked by robots.txt | Specific pages or directories are blocked by robots.txt. | Review and adjust robots.txt file. Ensure that important pages are not blocked by incorrect settings. |
| 404 errors | Broken links or missing pages. | Fix broken links by updating the broken links to their correct destinations. If a page is permanently removed, implement a 301 redirect to the relevant page or a 410 status code. |
| 5xx Server Errors | Temporary or permanent server issues preventing access to pages. | Identify and fix server-side problems. This may require contacting your hosting provider or checking server logs for specific errors. |
| 301 redirects | Permanent redirects that aren’t handled correctly. | Ensure redirects are set up correctly and point to the correct destination. Confirm that redirects don’t create a redirect loop. |
Optimizing Crawl Performance
Understanding how Googlebot crawls your website is crucial for achieving high search rankings. Effective optimization of crawl performance ensures your site’s content is discovered and indexed efficiently, leading to improved visibility in search results. This involves understanding the factors influencing crawl efficiency and implementing strategies to enhance the process.Site structure and navigation significantly impact how easily Googlebot can traverse your website.
A well-organized structure, with clear hierarchies and logical links, facilitates the crawling process. Conversely, a confusing or poorly structured site can hinder Googlebot’s ability to explore and index all relevant content.

Google Search Console crawl stats are crucial for understanding how often Googlebot visits your site. A minimalist design, while visually appealing, can sometimes impact these stats. Factors like fewer JavaScript files and optimized images can actually improve your site’s performance and crawlability, which is where the importance of minimalist website help or hurt comes in. Ultimately, a well-structured minimalist website can significantly improve your Google Search Console crawl stats.
Site Structure and Navigation
A well-structured website acts as a roadmap for Googlebot, guiding it through the different pages and content. Clear hierarchies and logical link structures are essential for efficient crawling. Implementing a logical sitemap, incorporating internal linking strategies, and using descriptive anchor text improve Googlebot’s understanding of the site’s architecture and the relationships between pages. A user-friendly navigation structure is often a direct reflection of a site’s organizational structure and facilitates ease of access for both users and Googlebot.
Site Speed
Site speed is a critical factor in crawl efficiency. A slow-loading website can negatively impact Googlebot’s ability to crawl and index content. Googlebot, like any web crawler, has limited resources and time to spend on a single website. A slow site may result in Googlebot spending less time on your pages, potentially missing important updates or new content.
Improving Googlebot Crawling Efficiency
Several methods can enhance the efficiency of Googlebot crawling. Prioritizing high-quality content that is regularly updated helps Googlebot understand the value of your site. A well-maintained robots.txt file allows you to explicitly control which parts of your site Googlebot should or should not crawl. Using structured data markup can improve the comprehensibility of your website’s content, aiding in accurate indexing.
Employing effective canonicalization strategies, especially for duplicated content, can help Googlebot correctly understand and index the original content.
Relationship Between Website Speed and Crawl Efficiency
| Website Speed | Crawl Efficiency | Impact |
|---|---|---|
| Fast | High | Improved indexing and better search rankings. |
| Slow | Low | Potential indexing issues and lower search rankings. |
A fast website allows Googlebot to quickly process and index pages, leading to more comprehensive indexing and potentially better search rankings. Conversely, slow websites may result in incomplete indexing and potentially lower search rankings. Site speed is a key component of user experience, and Google prioritizes sites that provide a positive user experience, which includes loading time. A fast site often correlates with improved user engagement and conversion rates, which Google considers when evaluating search ranking.
Utilizing Crawl Stats for Improvement
Crawl stats, while seemingly technical, are a goldmine of actionable insights for website optimization. They reveal how search engines perceive your site, pinpointing areas needing improvement before they affect your search ranking. By diligently monitoring and analyzing these stats, you can proactively address issues and maximize your website’s visibility.Understanding crawl data isn’t just about fixing errors; it’s about understanding your audience’s experience and aligning your website to meet their needs more effectively.
This understanding allows you to tailor your content strategy and site structure to better serve your target audience and improve your search engine rankings.
Utilizing Crawl Data for Website Improvements
Crawl data provides a detailed roadmap for identifying and resolving website issues. It shows which pages are being crawled, how often, and the speed at which they are indexed. This information is invaluable in optimizing website performance. Using this data, you can identify bottlenecks in the indexing process and optimize for faster crawl rates, ultimately leading to quicker updates in search engine results pages (SERPs).
Correlating Crawl Data with Website Traffic
A direct correlation between crawl data and website traffic isn’t always straightforward. However, by analyzing crawl data, you can identify patterns that influence traffic. For example, if crawl errors are consistently found on pages with high traffic, you can infer a potential relationship between these errors and reduced user engagement. By resolving these errors, you can potentially increase traffic by enhancing the overall user experience.
Strategies for Leveraging Crawl Data in Content Planning
Crawl data can inform content planning in several ways. If crawl data shows a significant amount of crawling activity on certain topics, it suggests high user interest in those areas. This data can be used to develop future content strategies, potentially focusing on related topics, and creating content that addresses these identified interests.
Best Practices for Implementing Changes Based on Crawl Data Analysis, Google search console crawl stats
Implementing changes based on crawl data analysis should be approached systematically. Begin by prioritizing the most critical issues, focusing on those that directly affect user experience or crawl performance. This includes resolving crawl errors, improving site structure, and optimizing page speed. Thorough documentation of changes, and their corresponding impact on crawl data, is essential.
Case Study: Addressing Crawl Errors on an E-commerce Website
A case study reveals how crawl data helped improve an e-commerce site. The site was experiencing a high volume of 404 errors, leading to a drop in search engine visibility. Analysis of crawl data showed that these errors were predominantly due to outdated product URLs. By updating the product URLs, the site resolved the 404 errors. This direct action increased the site’s visibility, leading to a noticeable increase in organic traffic.
The improved crawl data reflected the positive impact of the change.
Closure

In conclusion, harnessing the power of Google Search Console crawl stats is key to understanding and optimizing your website’s performance in search results. By interpreting crawl data effectively, you can identify and address issues promptly, ensuring your website is accessible and well-indexed by search engines. By understanding the relationship between crawl efficiency and website speed, you can strategically optimize your site for better search rankings.
Ultimately, using crawl stats to inform website improvements is a powerful strategy for long-term success in the digital landscape.