
The Precision Trap: Understanding the Critical Distinction Between Ordinal and Interval Scales in Modern Data Analysis
The human impulse to categorize and rank is a fundamental aspect of cognitive processing, influencing everything from educational priorities to corporate performance metrics. In daily life, individuals frequently seek to establish hierarchies, asking which university holds the top position, which salesperson leads the quarterly revenue charts, or how personal values should be prioritized. This sequencing of information provides a sense of order and clarity in a complex world. However, statistical experts and data visualization specialists warn that a common logical fallacy persists in the way these sequences are interpreted: the conflation of ordinal scales with interval scales. While a ranked list provides a sequence, it does not inherently provide a quantitative measure of the distance between the items in that sequence. This distinction is not merely academic; it has profound implications for how data is analyzed, reported, and used to inform critical decision-making in business, science, and social policy.
The Taxonomy of Measurement: Ordinal versus Interval
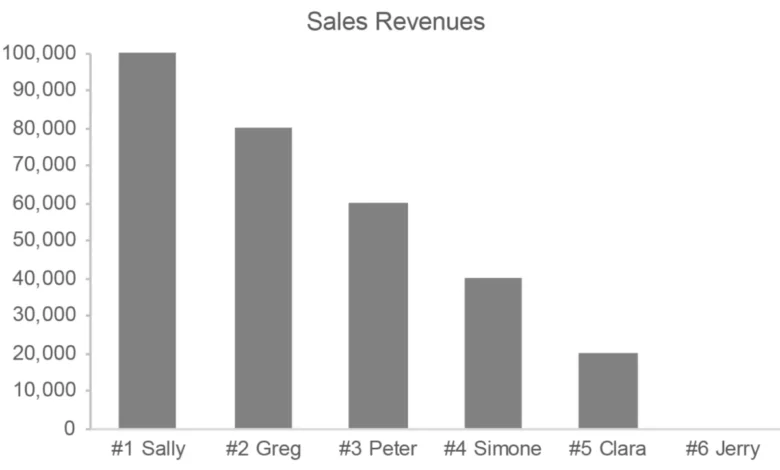
To understand the risks of data misinterpretation, one must first distinguish between the fundamental types of scales used in data sensemaking. An ordinal scale is defined by a meaningful order or sequence. In an ordinal system, the relative position of items is known, but the precise magnitude of the difference between them is not. For example, in a list of salespeople ranked by performance, the #1 rank identifies the top performer and the #2 rank identifies the second. However, this ranking reveals nothing about the actual revenue gap between the two. The top salesperson might have outperformed the second by a negligible margin, or they might have generated double the revenue. The "distance" between ranks is inconsistent and non-quantitative.
In contrast, an interval scale is characterized by equal, measurable distances between adjacent points. A standard interval scale subdivides a continuous range of quantitative values into uniform segments. A common example is time; the decade between 1950 and 1960 is of the exact same duration as the decade between 2010 and 2020. Similarly, on a temperature scale like Celsius, the difference between 20 and 30 degrees is the same as the difference between 30 and 40 degrees. Because interval scales are inherently quantitative, they allow for mathematical operations—such as addition and subtraction—that are technically invalid when applied to ordinal data.
The confusion between these two scales often leads to the "precision trap," where the appearance of a numerical sequence (1, 2, 3…) is mistaken for a measurement of quantity. In the context of data visualization, this distinction is critical. A graph displaying an interval scale provides a clear, objective representation of magnitude. A graph displaying an ordinal scale only shows a progression of categories, which can be highly misleading if the viewer assumes the gaps between categories are uniform.

Historical Context and the Hierarchy of Data
The formalization of these measurement levels dates back to 1946, when psychologist Stanley Smith Stevens published a seminal paper in Science titled "On the Theory of Scales of Measurement." Stevens proposed four levels of measurement: nominal, ordinal, interval, and ratio. This framework remains the gold standard for statistical analysis today.
Chronologically, the evolution of data measurement has moved from simple categorization (nominal) to the complex modeling used in modern data science. In the mid-20th century, the rise of social science research necessitated new ways to "measure" human attitudes and behaviors that were not easily quantifiable. This led to the widespread adoption of the Likert scale, developed by Rensis Likert in 1932. While Likert scales were designed to capture the intensity of feelings or opinions (e.g., "Strongly Disagree" to "Strongly Agree"), they are fundamentally ordinal.
Over the decades, as computational power increased and the demand for "hard numbers" in corporate and academic environments grew, a trend emerged toward treating these ordinal responses as interval data. By assigning the number 1 to "Never" and 5 to "Always," researchers began calculating averages and standard deviations for data that was never intended to support such arithmetic. This shift marked a significant turning point in data reporting, moving away from qualitative nuance toward a perceived, but often false, sense of mathematical objectivity.
The Likert Scale Controversy in Social Science
The Likert scale is perhaps the most ubiquitous example of an ordinal scale being misused as an interval scale. In surveys ranging from customer satisfaction to clinical psychological assessments, respondents are asked to select from an ordered list:
- Never
- Seldom
- Occasionally
- Frequently
- Always
The fundamental issue is that the "distance" between "Never" and "Seldom" is not necessarily equal to the distance between "Frequently" and "Always." Furthermore, a respondent who selects "Always" (5) is not expressing a sentiment that is five times "greater" than a respondent who selects "Never" (1). Despite this, it is common practice in many industries to "quantify" these responses. In a clinical setting, a patient’s "depression score" might be calculated by summing their numerical responses to various Likert-style questions.

Critics of this approach, including many contemporary statisticians, argue that this renders the resulting data suspect. If the underlying scale is not truly quantitative, the resulting "average score" is a statistical phantom. For instance, if a company receives two customer satisfaction ratings—one "5" (Excellent) and one "1" (Poor)—the average is a "3" (Average). However, this average does not represent the reality of two polarized customers; it creates a mathematical middle ground that does not exist in the raw data. This practice, while convenient for high-level reporting, can obscure critical insights and lead to flawed organizational strategies.
Data Visualization and the Distortion of Reality
In the field of data visualization, the misuse of ordinal rankings can dramatically distort the perception of performance. When values are ranked from high to low, the resulting graph often implies a linear or uniform progression that may not exist. Consider three different scenarios for a sales team:
- Uniform Progression: The difference between each rank is consistent (e.g., each salesperson sells $10,000 less than the person above them).
- Top-Heavy Dominance: The #1 salesperson generates $1 million in revenue, while the #2 salesperson generates only $200,000.
- Clustered Performance: The top five salespeople are separated by only a few dollars, while the sixth salesperson lags significantly behind.
In an ordinal ranking list, all three scenarios look identical: 1, 2, 3, 4, 5, 6. If a manager makes decisions based solely on the ranking, they might miss the fact that in Scenario 2, the company is dangerously dependent on a single individual, or that in Scenario 3, the "bottom" performers are actually nearly as effective as the "top" performers. Experts argue that for most analytical purposes, the actual quantitative values (the interval or ratio data) are far more important than the ordinal rankings. Rankings should be used to organize a display for easier comparison, but they should not be the primary focus of the analysis itself.
Professional Perspectives and Industry Implications
The debate over ordinal quantification has created a divide between academic rigor and corporate convenience. Many business analysts defend the practice of averaging Likert scales, citing the "Law of Large Numbers" and the practical need for simplified KPIs (Key Performance Indicators). They argue that as long as the methodology is consistent, the resulting trends are still useful for tracking performance over time.
However, statisticians caution that this convenience comes at a high cost. Dr. Jamieson, a noted researcher in medical education, has argued that treating ordinal data as interval data is a "misconception" that can lead to erroneous conclusions in peer-reviewed research. In the corporate world, this can manifest as misallocated resources. If a department is penalized for a "3.2" satisfaction rating versus a "3.4" rating, but the difference is statistically insignificant due to the ordinal nature of the survey, the organization may be chasing "noise" rather than meaningful improvement.

Furthermore, there is the issue of "inflation of precision." By presenting a satisfaction score as "4.27 out of 5," organizations lend their findings an air of scientific accuracy and objectivity. This can be used—intentionally or unintentionally—to bolster research claims or justify administrative decisions that might otherwise be questioned if the data were presented in its true, qualitative form.
Broader Impact and the Path to Data Literacy
The implications of conflating ordinal and interval scales extend beyond the boardroom and the laboratory. In the era of Big Data and algorithmic decision-making, the integrity of the input data is paramount. Algorithms that are fed "quantified" ordinal data may produce biased or incorrect outputs, affecting everything from credit scoring to public health recommendations.
To combat these issues, there is a growing movement toward improved data literacy. Educators and industry leaders are emphasizing the importance of understanding the "why" behind the numbers. This involves:
- Recognizing the Scale: Identifying whether a data set is nominal, ordinal, interval, or ratio before beginning analysis.
- Appropriate Visualization: Using bar charts or dot plots that reflect actual quantitative values rather than just ranked positions.
- Contextual Reporting: Accompanying numerical summaries with a breakdown of the distribution of responses to ensure the nuance of ordinal data is not lost.
In conclusion, while the human tendency to put things in order is an essential tool for navigating life, it must be tempered with statistical discipline. Ordinal scales provide a valuable way to arrange and compare items, but they are not a substitute for quantitative measurement. In science, data sensemaking, and visualization, maintaining the distinction between the sequence of items and the distance between them is the hallmark of accurate and ethical analysis. As the world becomes increasingly data-driven, the ability to recognize and avoid the "precision trap" will be a defining skill for researchers, analysts, and leaders alike.


{kind=link}