
The Strategic Blueprint for Social Media Success: Unpacking the Power of Content Pillars
A robust social media marketing strategy transcends mere consistent posting; it hinges on the creation of diverse and engaging content that captivates and retains audience attention. A fundamental approach to achieving this lies in the establishment of social media content pillars—core themes that provide focus, purpose, and strategic alignment to a brand’s online presence. Originality, a key differentiator, is paramount. According to the 2025 Sprout Social Index, consumers identify content originality as a primary factor for brands to stand out, ranking it second only to service quality. This article delves into the nature of social media content pillars, explores their application by leading brands, and offers a step-by-step guide for developing them to refine social content output.
Defining the Pillars of Social Media Engagement
At their core, social media content pillars are the principal themes or categories of content that a brand consistently produces and distributes across its social media platforms. Each pillar is typically designed to serve a specific objective, resonate with a particular audience segment, or adopt a distinct content format. The term "pillars" aptly describes their function as structural supports for a brand’s social media strategy, ensuring consistency and relevance across all digital touchpoints, much like the foundational columns of an architectural marvel.
Ideally, these pillars should exhibit overlap across a brand’s entire social media portfolio. However, their prominence may vary depending on the unique audience demographics and platform-specific features. For instance, a pillar focused on trendspotting might be more extensively utilized on a platform like TikTok than on LinkedIn. As a general guideline, brands are advised to maintain between three to five content pillars at any given time. An excessive number can dilute the brand’s core message and dilute its impact. For a food and beverage brand, potential pillars could encompass recipe demonstrations, behind-the-scenes glimpses of ingredient sourcing, customer testimonials, and spotlights on seasonal offerings. These examples serve as a starting point, with real-world case studies offering further inspiration for tailoring pillars to individual brand identities.

The Indispensable Role of Content Pillars in Social Media
The implementation of content pillars significantly streamlines the content planning process, providing clear direction on the type of content to be created and its underlying purpose. Pillars ensure that each post serves a distinct function, speaks to a specific audience segment, and reinforces the brand’s overarching identity. When content is meticulously aligned with defined pillars, messaging remains coherent and consistent across all social media channels. Furthermore, these pillars encourage content diversification, ensuring a regular cadence of varied and engaging posts.
Exemplary Content Pillars Across Industries
Brands across diverse sectors are leveraging content pillars to achieve specific marketing objectives. These examples, while illustrative, underscore the need for tailoring pillars to reflect unique brand values and audience characteristics.
Brand Messaging and Storytelling: Building Identity and Trust
Brand messaging and storytelling pillars center on themes that embody a brand’s core identity. This can manifest as Instagram Reels showcasing company history, carousel posts detailing mission statements, or promotional videos visualizing brand positioning. Such content is instrumental in building brand awareness, fostering trust, and cultivating strong customer relationships. It can also be a powerful tool for recruitment.
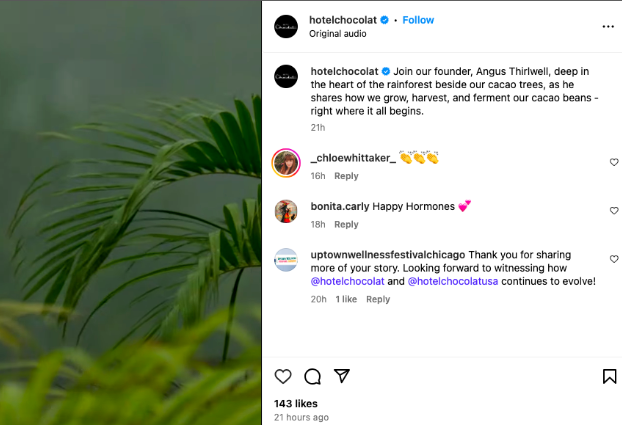
The flexibility of this pillar is considerable, with success hinging on the seamless integration of content with the brand narrative. Hotel Chocolat, a UK-based chocolate manufacturer, exemplifies this with an Instagram Reel featuring its founder on location at the company’s first cacao farm. This video effectively narrates the brand’s product origins and company history, leveraging its distinct heritage to create content that is uniquely its own and highly resonant with its audience.
Entertaining Content: Capturing Attention and Broadening Reach
Entertaining content aims to connect with audiences on an emotional level, offering moments of levity and enjoyment. This can range from comedic sketches and engaging podcast conversations to professionally produced advertisements designed for maximum entertainment value. Entertaining content not only enhances brand awareness but also significantly increases content reach, especially when integrated with prevailing social media trends.
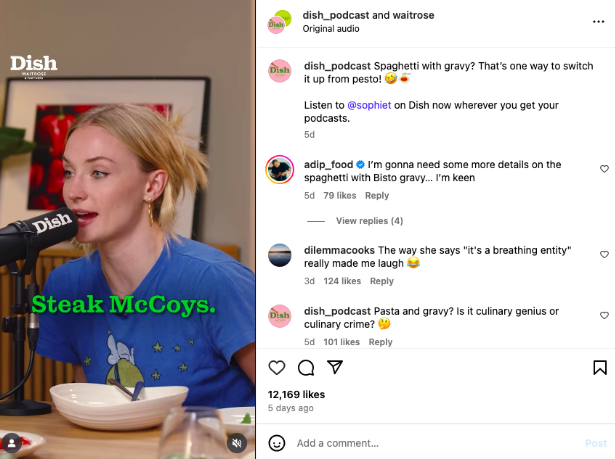
The creation of compelling entertaining social media content is a dynamic and evolving challenge. Brands are encouraged to research how competitors engage their audiences through entertainment and to adapt trends authentically. Waitrose, a prominent UK supermarket chain, utilizes its "Dish" podcast as an entertaining content pillar. Co-hosted by celebrity chef Angela Hartnett and UK radio personality Nick Grimshaw, the podcast blends the popular interests of entertainment and food. By featuring celebrity guests and food-focused interviews, Waitrose effectively engages viewers while maintaining relevance to its brand offerings. This approach demonstrates how to leverage influencer marketing and engaging narratives to capture audience attention.
Promotional and Product-Focused Content: Driving Conversions and Sales
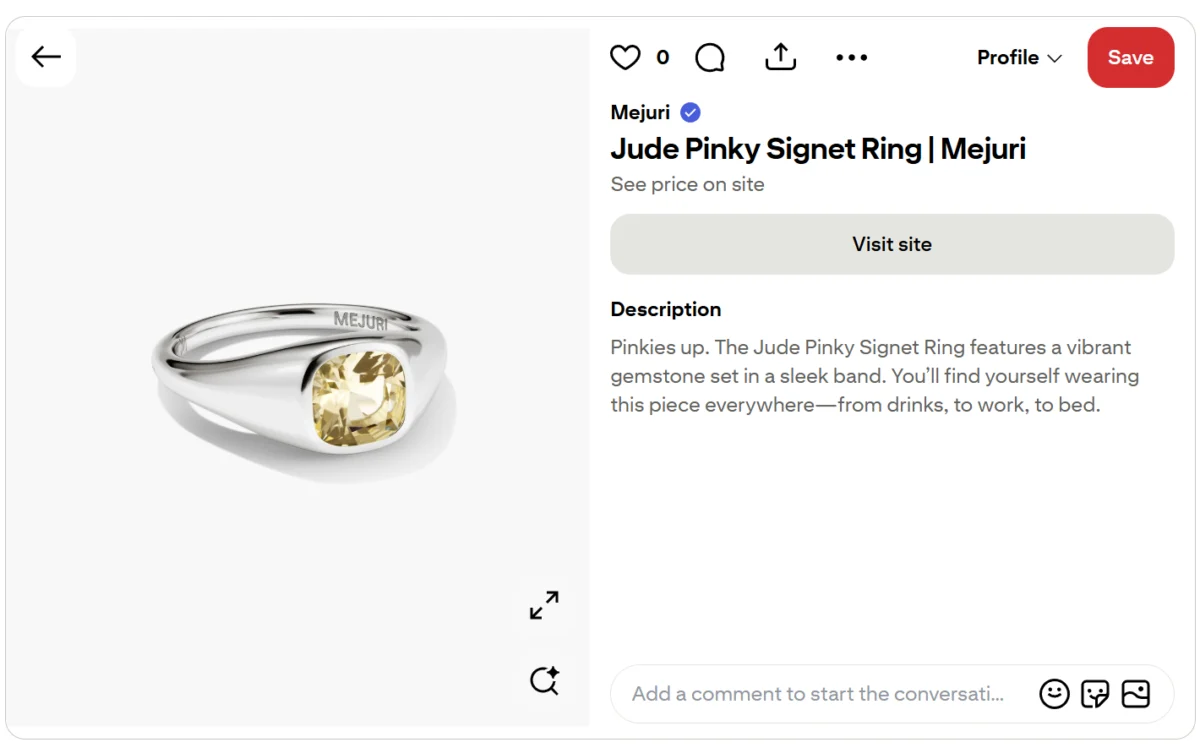
This pillar is dedicated to content specifically designed to promote products and services. It can include detailed breakdowns of software features, demonstrations of service functionalities, or reels showcasing real-world product usage. Often, this pillar intersects with time-sensitive sales and promotional events, such as Black Friday. The primary objective of promotional content is to convert social media followers into paying customers.
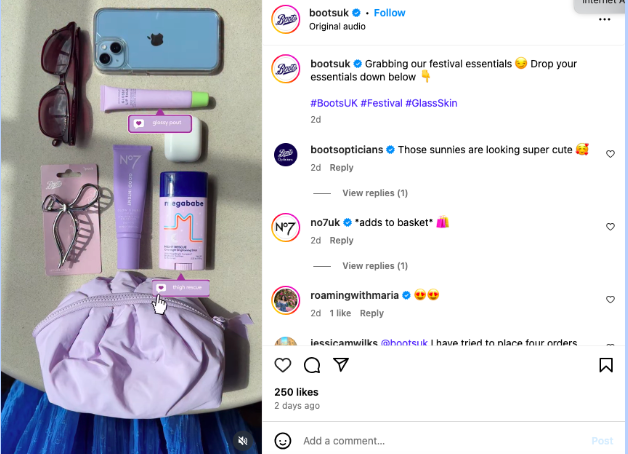
Boots, a UK pharmacy chain, effectively employs this pillar by promoting products tailored for festival-goers. This content is strategically timed to coincide with the peak UK festival season, targeting a specific audience with relevant offerings. Such posts frequently rely on a well-structured social media content calendar to ensure timely delivery of promotional messages, driving traffic towards exclusive deals and increasing conversion rates.
User-Generated Content (UGC): Amplifying Reach and Fostering Loyalty
User-generated content (UGC) represents a powerful and often cost-effective content pillar, particularly for marketing teams with limited resources. UGC campaigns empower audiences to create and share content on behalf of the brand, encompassing activities like product testing, competitions, and charity challenges.
UGC significantly expands a brand’s reach and engagement by leveraging brand advocates to enhance visibility within niche communities. It also plays a crucial role in building and nurturing customer loyalty, keeping the brand top-of-mind. Beyond lightening the content creation burden, UGC cultivates deeper engagement, fosters trust, strengthens community bonds, and sparks organic conversations around the brand.
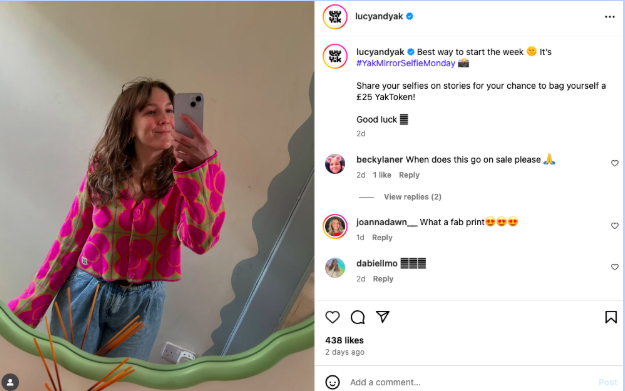
Lucy & Yak, a UK clothing brand, effectively capitalizes on UGC through its recurring #YakMirrorSelfieMonday campaign. By incentivizing content creation with a £25 "YakToken" for winners, the brand encourages customers to share product photos, thereby advertising its offerings while simultaneously fostering a strong sense of community engagement. This initiative highlights the power of recurring content drops and incentive programs in maximizing UGC impact.
Crafting Your Brand’s Social Media Content Pillars: A Strategic Roadmap
Developing effective social media content pillars requires a systematic approach. The following steps provide actionable guidance for brands seeking to establish their unique content framework.
Step 1: Define Your Brand’s Goals and Audience Personas
Content pillars should be viewed as strategic vehicles that propel brands toward their broader business objectives. The initial step involves a thorough review of overarching brand goals. Consider how each objective can be achieved through the strategic deployment of content pillars. This analysis should be closely aligned with audience personas, ensuring that each pillar serves a defined purpose that resonates with target demographics. Understanding what audiences seek from a brand’s content and aligning this with core objectives is crucial. Common objectives include raising brand awareness, generating leads, and strengthening community engagement. Clear social media goals and well-defined audience personas are foundational for developing enduring and impactful content pillars.
Step 2: Audit Existing Content for Themes and Performance
Even without a formal pillar strategy, most brands consistently produce social media content. A comprehensive audit of past posts is essential to identify patterns and assess performance. By analyzing top-performing content, brands can uncover recurring themes that can inform future pillar development. Aligning social media metrics with business goals is critical for tracking performance. Metrics such as comments and shares are vital for community-building initiatives, while reach and likes are key indicators for brand awareness campaigns. As highlighted in the 2025 Sprout Social Index, marketing leaders today prioritize overall engagement, audience growth, and social interactions as key success metrics. Identifying these patterns provides a data-driven foundation for formalizing content pillars.
Step 3: Select 3-5 Repeatable Content Pillar Themes
The next stage involves defining three to five core themes that will serve as the primary content pillars. Prioritize themes that have naturally emerged from the content audit. Subsequently, identify any gaps in the existing framework and develop one or two additional pillars to address these deficiencies. The objective is to strike a balance between the brand’s strategic priorities and the interests of its audience. This can be achieved by mapping the primary goals of each pillar and assessing their alignment with audience personas and core social media objectives. It is important to remember that content pillars are not immutable. They can be reviewed and adapted periodically to accommodate evolving business needs and emerging opportunities, reflecting the dynamic nature of social media.
Step 4: Plan Content Distribution Across Channels
Once content pillars are established, the focus shifts to implementing them across various social media channels. Each pillar should be adapted to suit the unique characteristics of each platform. For instance, a product-focused pillar might be presented as an Instagram Reel, a feature breakdown video on TikTok, or an interactive webinar on LinkedIn. For guidance on platform-specific content adaptation, Sprout’s 2026 Social Media Content Strategy Report offers data-driven insights into optimal content formats and types for each network.
Measuring the Impact of Your Social Media Content Pillars
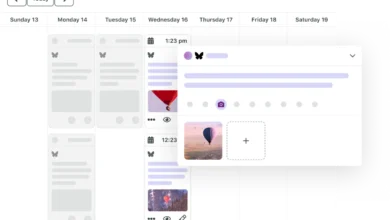
Consistent content creation around defined pillars necessitates robust performance measurement. Sprout Social’s Internal Tagging feature offers a streamlined approach to this process. By assigning a unique tag to each content pillar, brands can meticulously track the performance of every piece of content. This tagging system allows for a comprehensive overview of content diversification through the calendar view.
The Tag Performance Report then provides detailed insights into the effectiveness of individual content pieces within each pillar. Formalizing this process into a comprehensive tagging strategy enables brands to gain clearer insights into which pillars are most effective, which require refinement, and which may need to be retired or replaced. This data-driven approach to content performance analysis is crucial for continuous optimization and strategic agility.
Conclusion: Fortifying Social Media Performance with Content Pillars
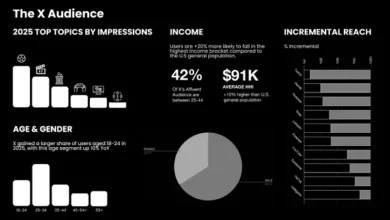
The implementation of well-defined social media content pillars empowers brands to create more effective content calendars and to more effectively achieve their overarching social media objectives. Enhanced insight into content performance facilitates the ongoing refinement of these pillars, ensuring sustained relevance and impact. For a deeper understanding of user expectations and strategic guidance on building future-ready social media teams, the 2025 Sprout Social Index is an invaluable resource. By integrating strategic content pillars with a comprehensive understanding of audience expectations, brands can significantly elevate their social media presence and achieve lasting digital marketing success.
Social Media Content Pillar FAQs
What are common mistakes teams make with social media content pillars?

A frequent oversight is failing to consider platform-specific nuances. While pillars should ideally overlap, their application must be tailored to the unique audiences and functionalities of each social network. Another common pitfall is the reluctance to adapt or evolve pillars over time, hindering a brand’s ability to remain relevant as its business and audience mature.
What are the three E’s of social media content pillars?
The foundational "three E’s" of social media content pillars are Engage, Entertain, and Educate. Every piece of content published on social media should aim to fulfill at least one of these core objectives, ensuring a balanced and purposeful content strategy.




{kind=link}